import pandas as pd
from sklearn.model_selection import train_test_split
import re
# Load the dataset
data = pd.read_csv('../../data/processed-data/brand_model_year_tax_data.csv').drop(
[
'The State Federal Information Processing System (FIPS) code',
'The State associated with the ZIP code',
'Number of returns [3]',
'City',
'State',
'Model Year',
'Make',
'Model',
'Electric Vehicle Type',
'Clean Alternative Fuel Vehicle (CAFV) Eligibility',
],
axis = 1
)
# Remove non-letters from columns names
regex = re.compile(r"\[|\]|<", re.IGNORECASE)
data.columns = [regex.sub("", col) if any(x in str(col) for x in set(('[', ']', '<'))) else col for col in data.columns.values]
data.columns = [re.sub(r'[0-9]', '', col).strip() for col in data.columns]
data.columns = [re.sub(r'/', '_', col) for col in data.columns]
# Group by 'ZIPCODE' and sum the 'Vehicle Count'
grouped_data = data.groupby('ZIPCODE')['Vehicle Count'].sum().reset_index()
# Selecting columns L to CY (indexes 11 to 102)
features_to_use = data.columns[2:]
# Ensuring correct selection of numeric columns
numeric_features_to_use = data[features_to_use].select_dtypes(include=['number']).columns
# Grouping these features by ZIPCODE and summing them
grouped_features = data.groupby('ZIPCODE')[numeric_features_to_use].sum().reset_index().drop('Vehicle Count', axis = 1)
# Merging the summed Vehicle Count with the grouped features on ZIPCODE
merged_data = grouped_data.merge(grouped_features, on='ZIPCODE')
# Extracting the features (X) and target (y)
X_grouped = merged_data[numeric_features_to_use]
y_grouped = merged_data['Vehicle Count']
# Splitting the data into training and testing sets
X_train_grouped, X_test_grouped, y_train_grouped, y_test_grouped = train_test_split(
X_grouped, y_grouped, test_size=0.2, random_state=42)Log-Transform Predictors
Electric Vehicle Data Analysis
Introduction
Create scatterplots to see the relationship between the independent variable and predictors. Perform a log transformation on features to normalize and compare original to transformed distribution.
Import Libraries & Data, Create Train/Test Datasets
Scatterplot Relationship - Predictor vs. Independent Variable
import matplotlib.pyplot as plt
# Scatter plots to understand relationship between predictors and independent variable
for i, feature in enumerate(features_to_use):
plt.figure(figsize=(10,5))
plt.scatter(X_grouped[feature], y_grouped, c="lightblue", edgecolors="blue")
plt.title(f'{feature} vs. Vehicle Count Relationship')
plt.xlabel(feature)
plt.ylabel('Vehicle Count')
plt.savefig(f'../../results/figures/scatterplots/{feature}_scatterplot.png')
plt.show()
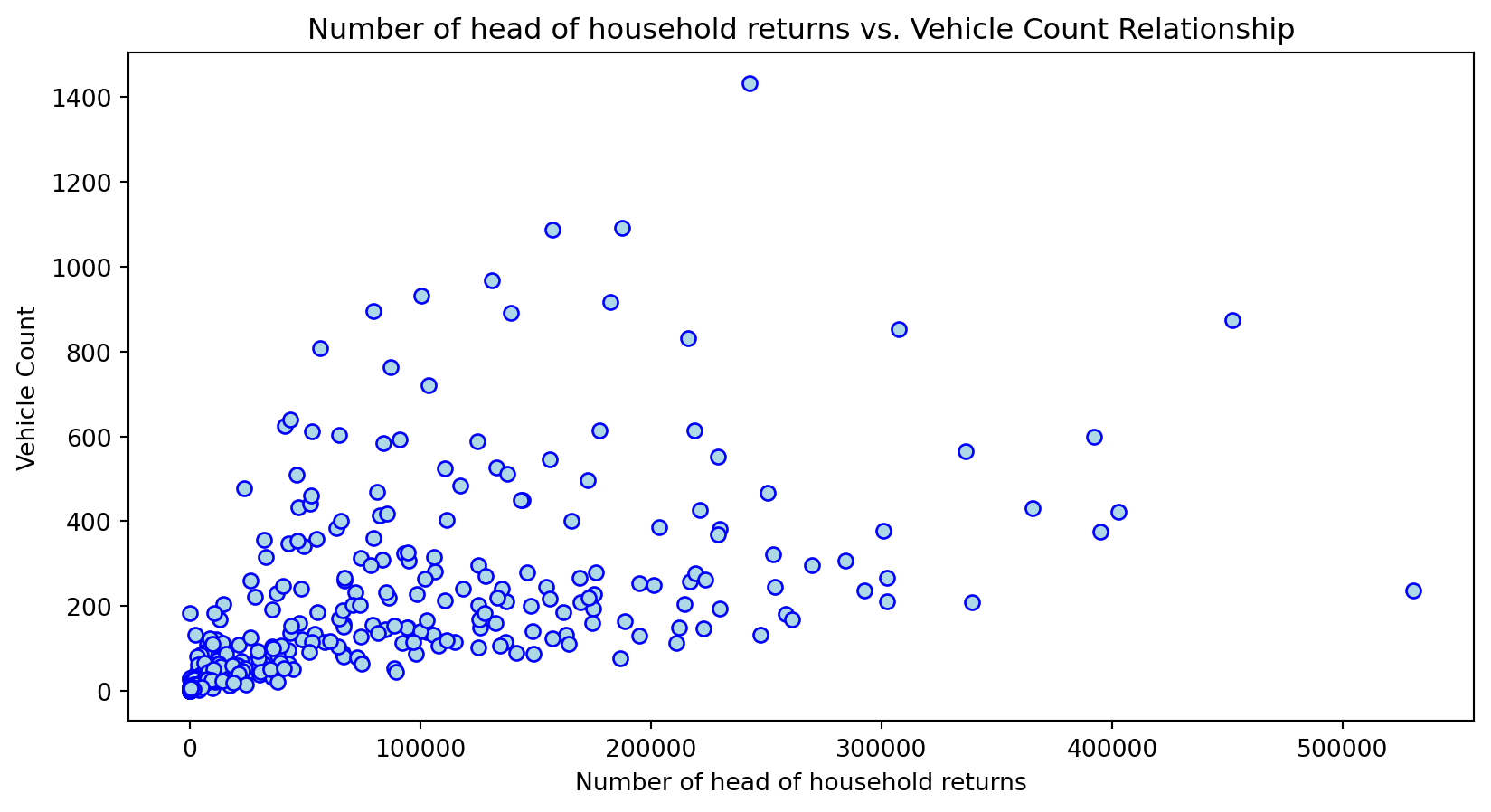
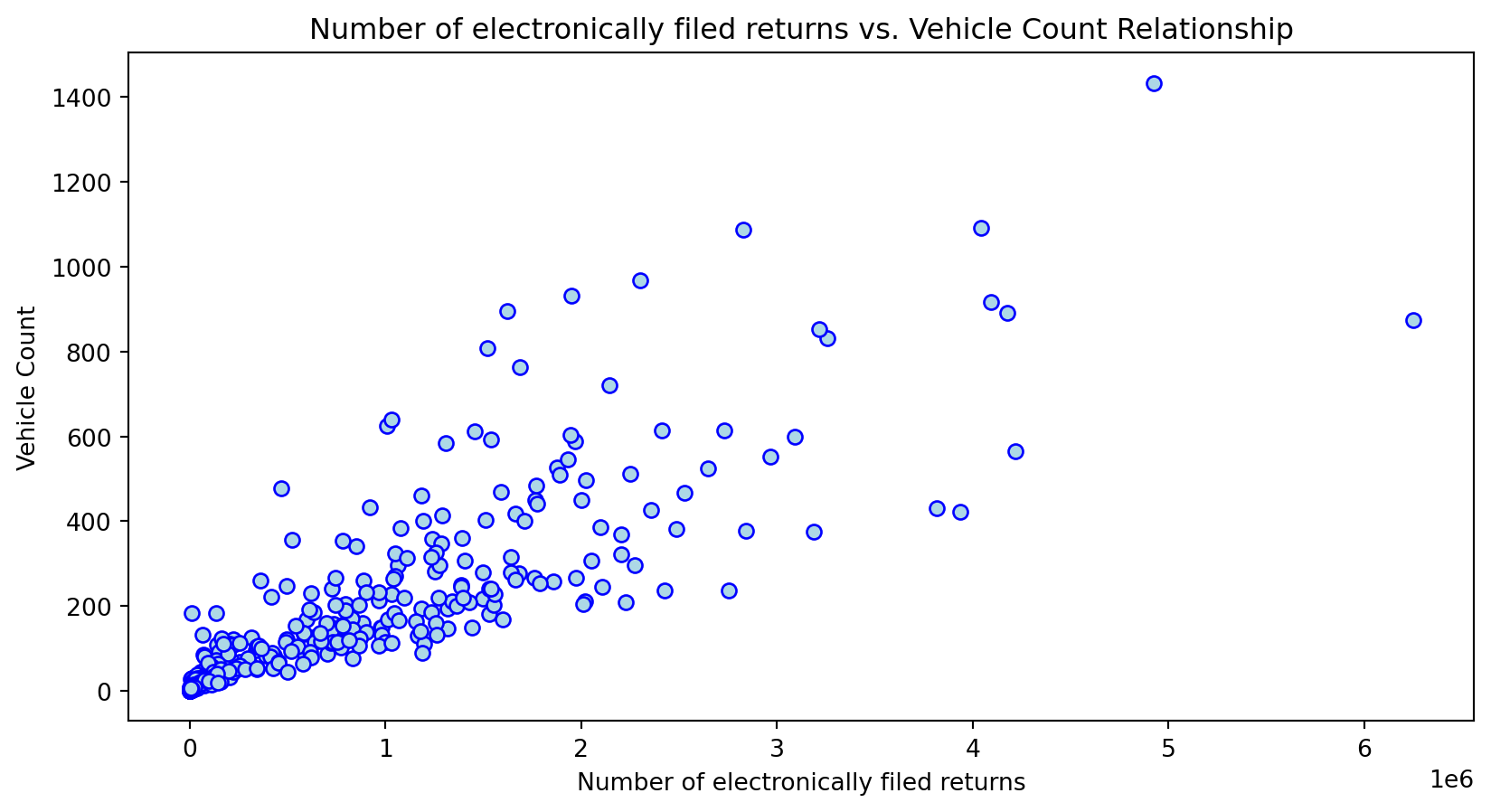
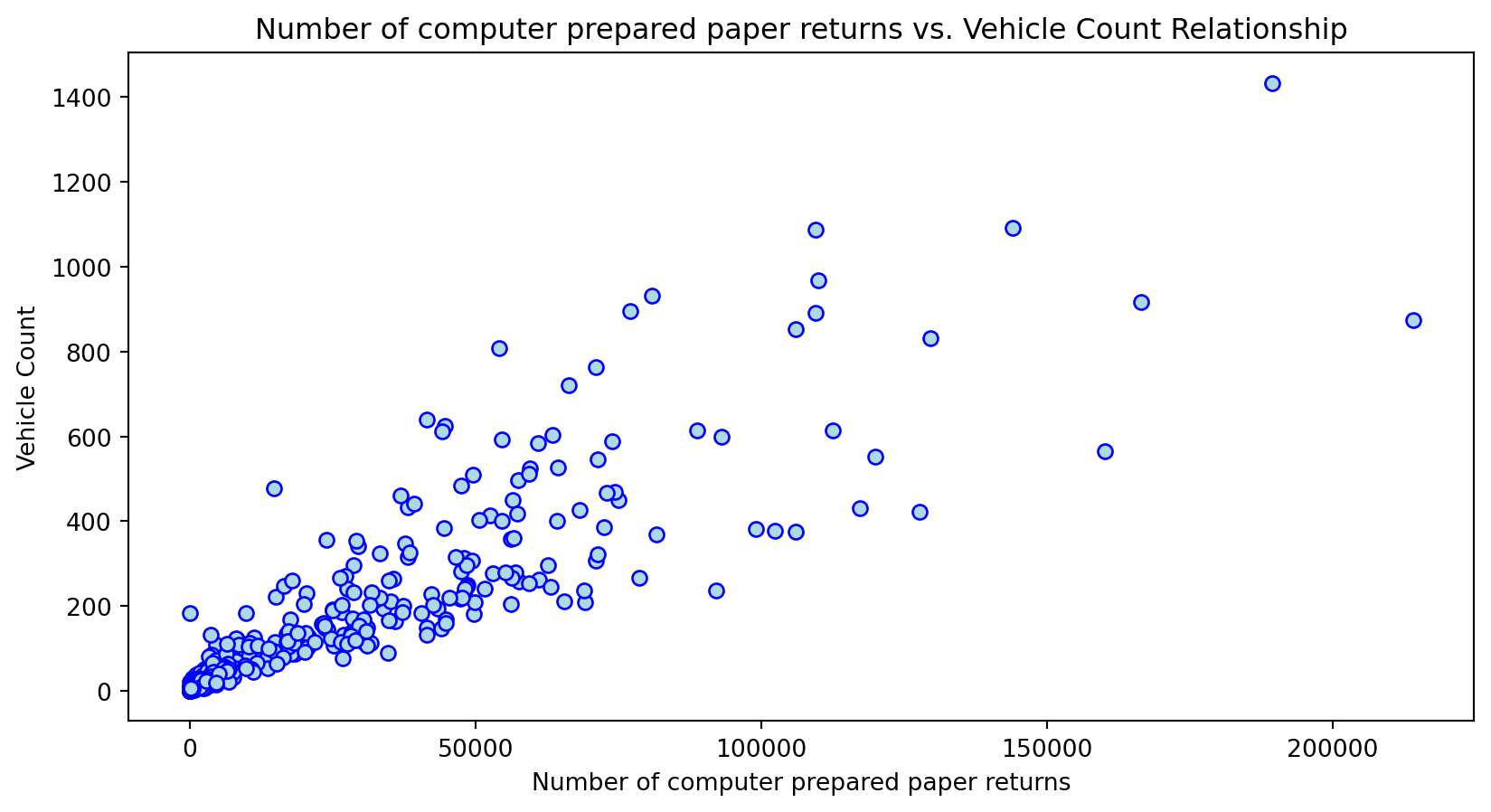
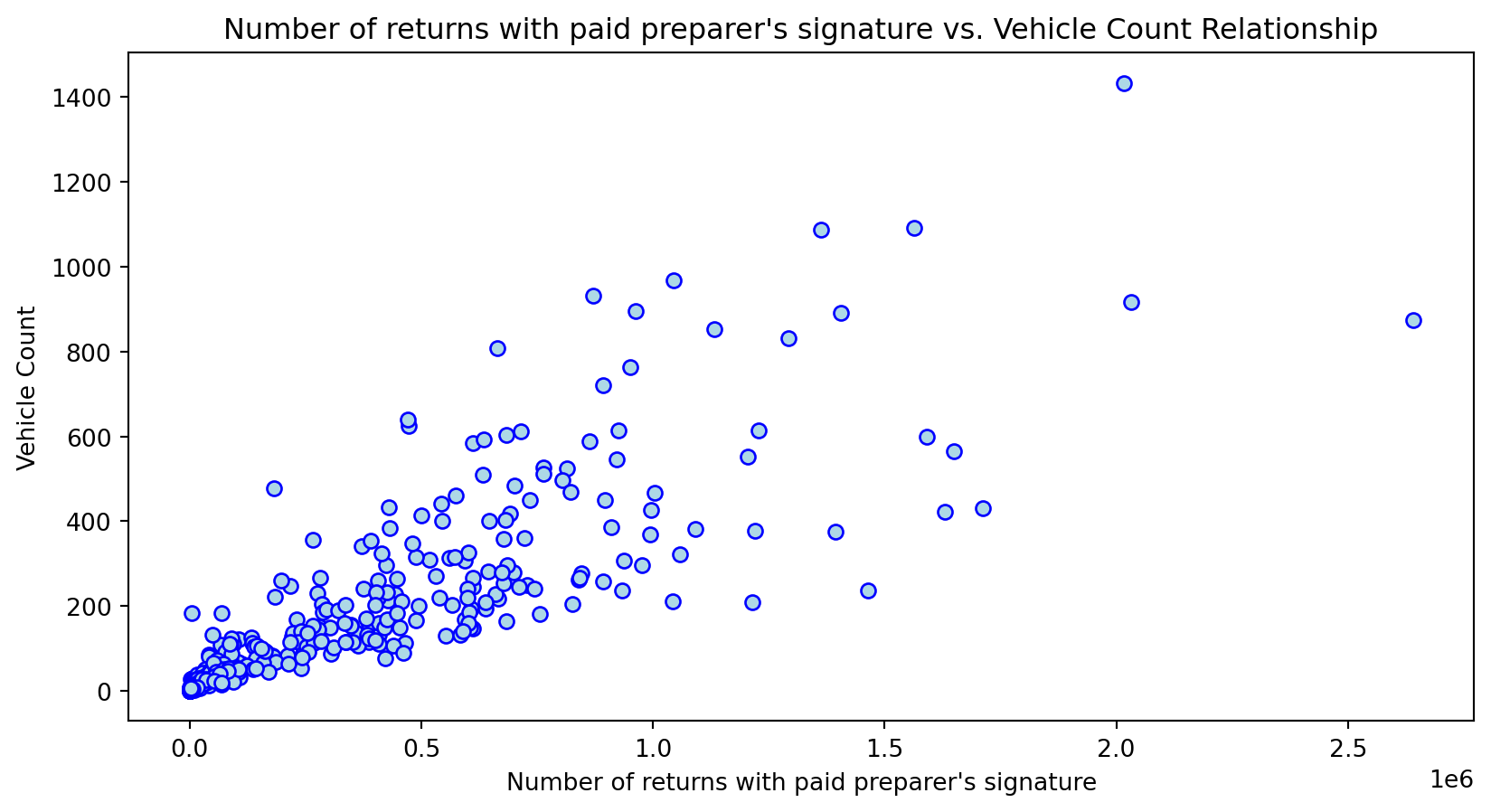
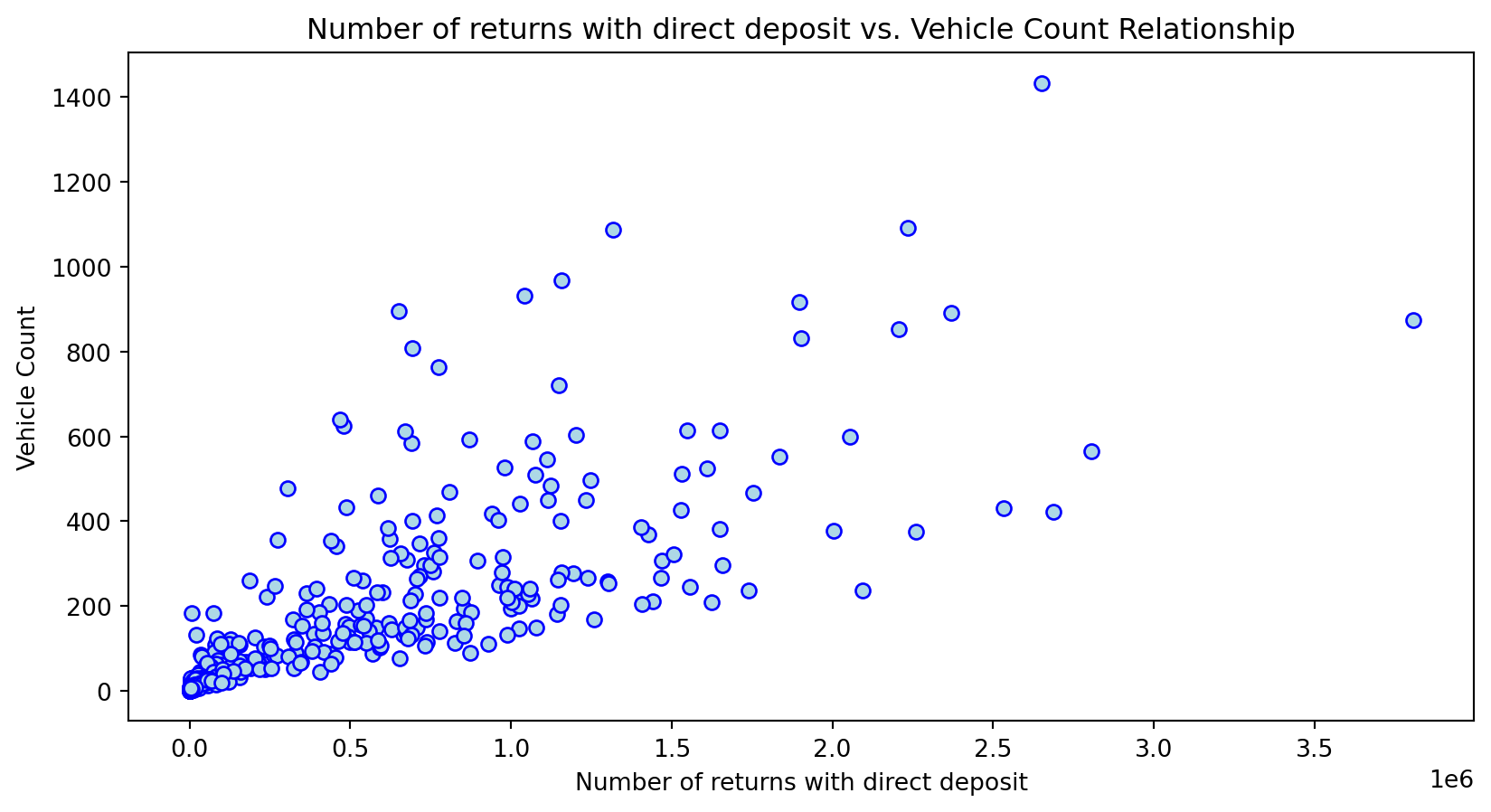
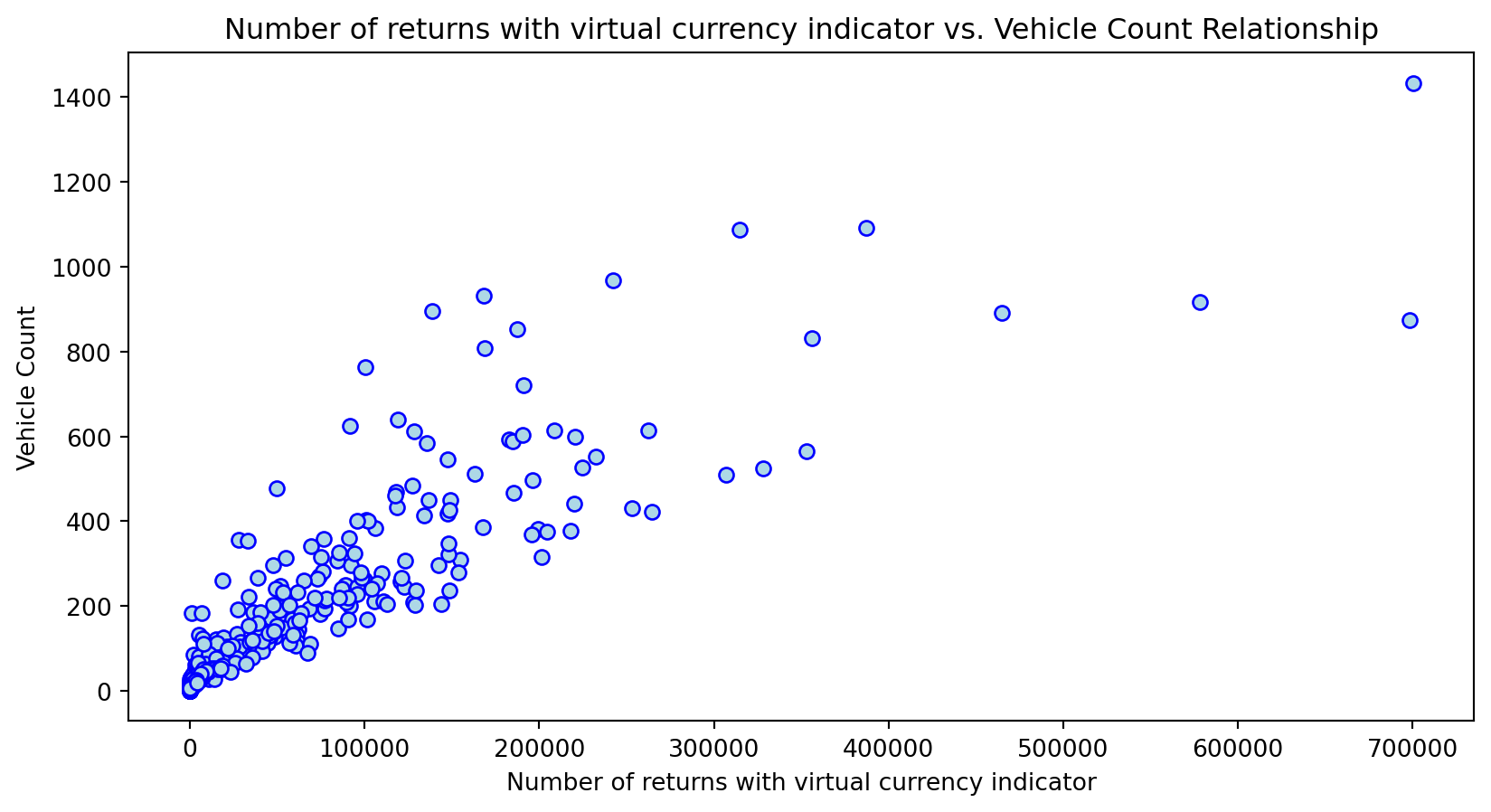
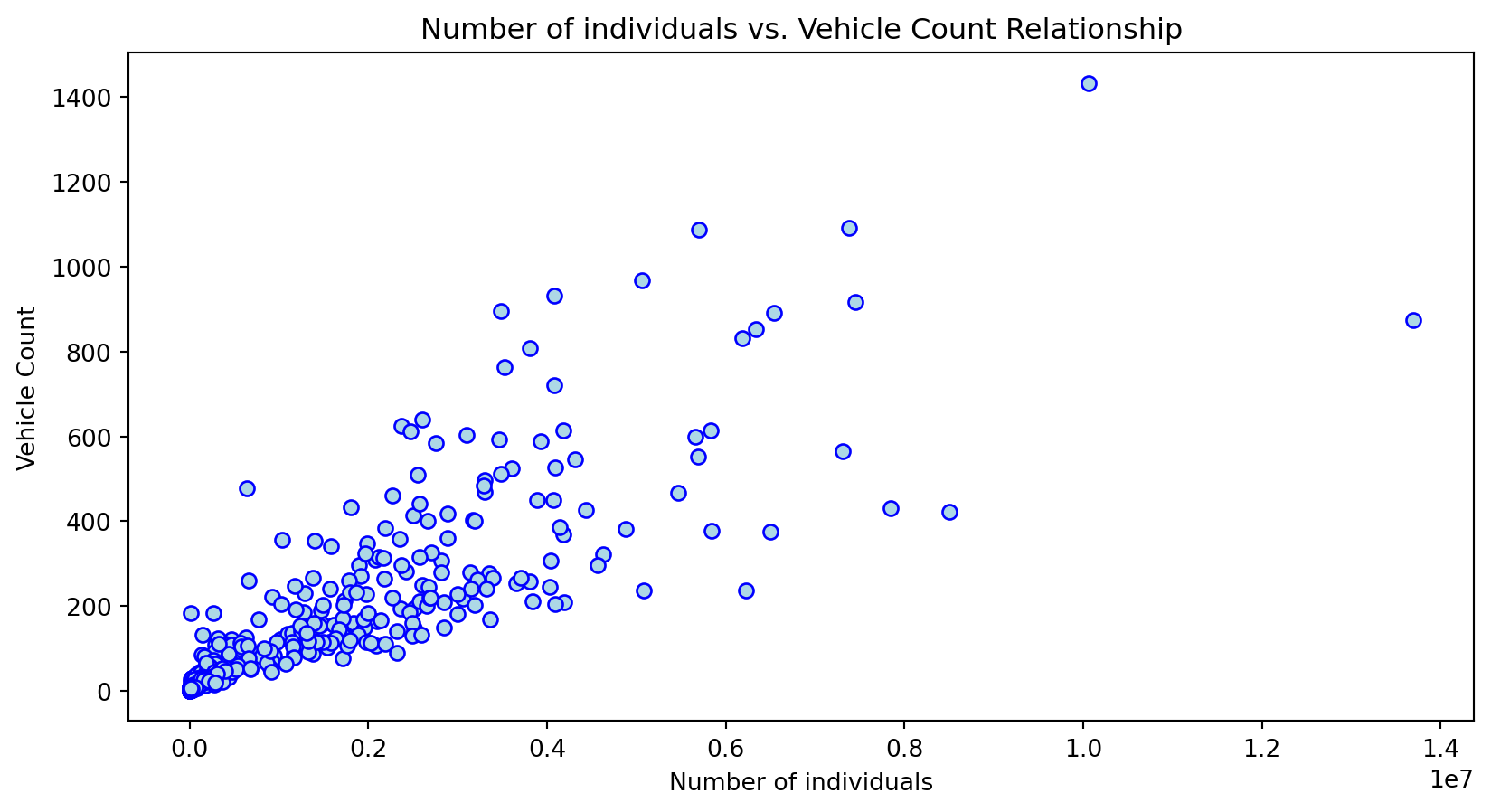
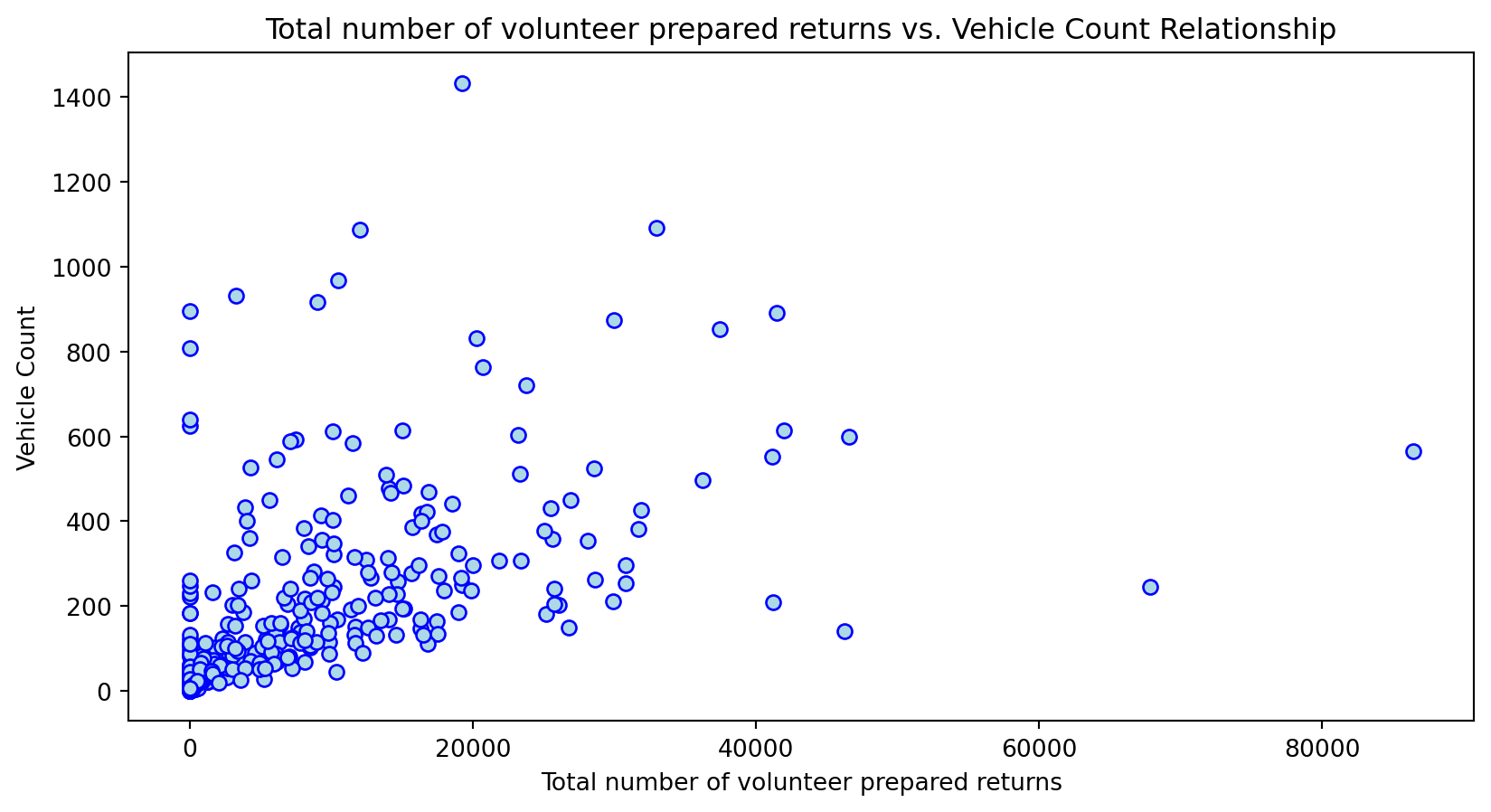
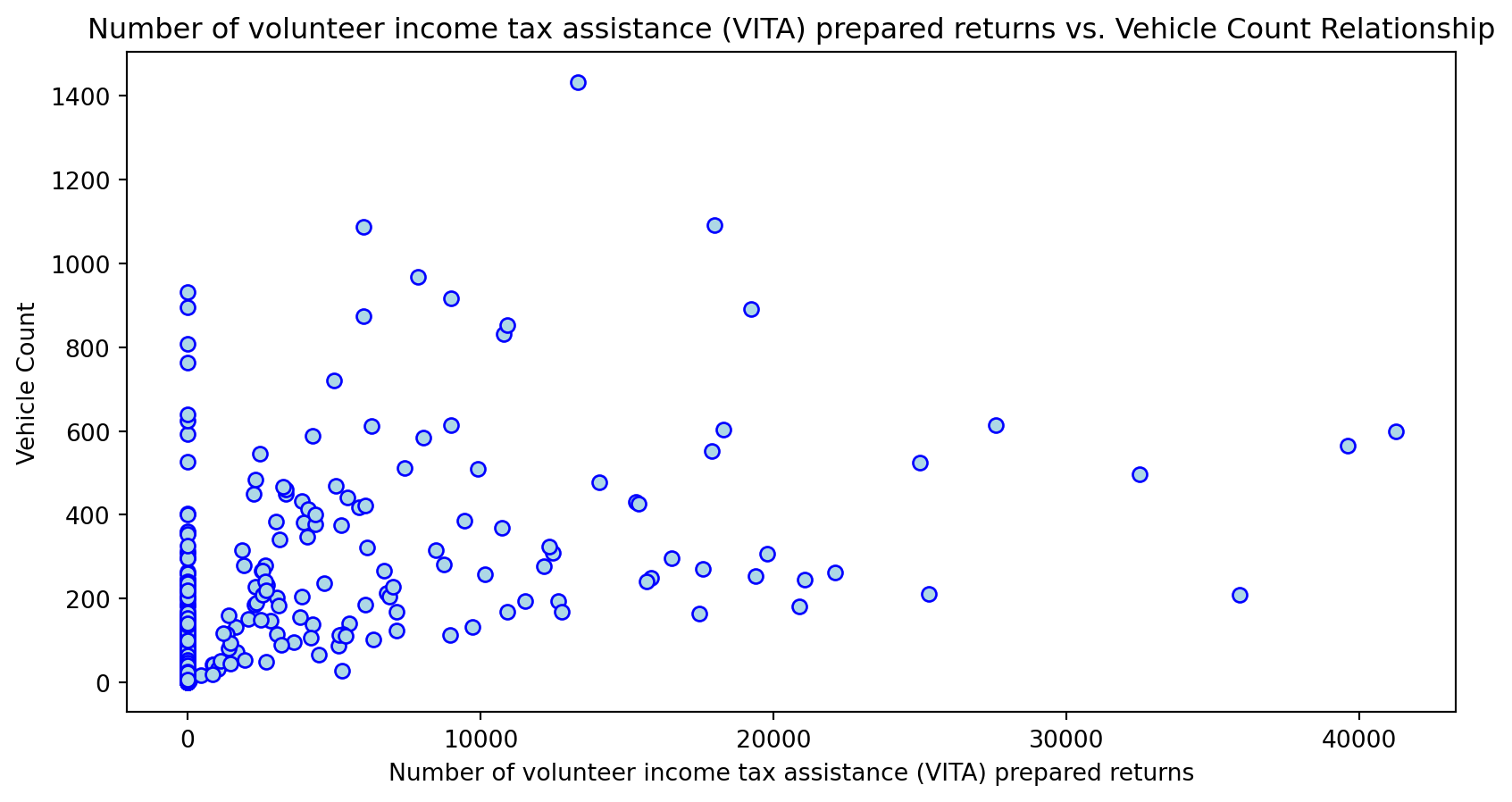
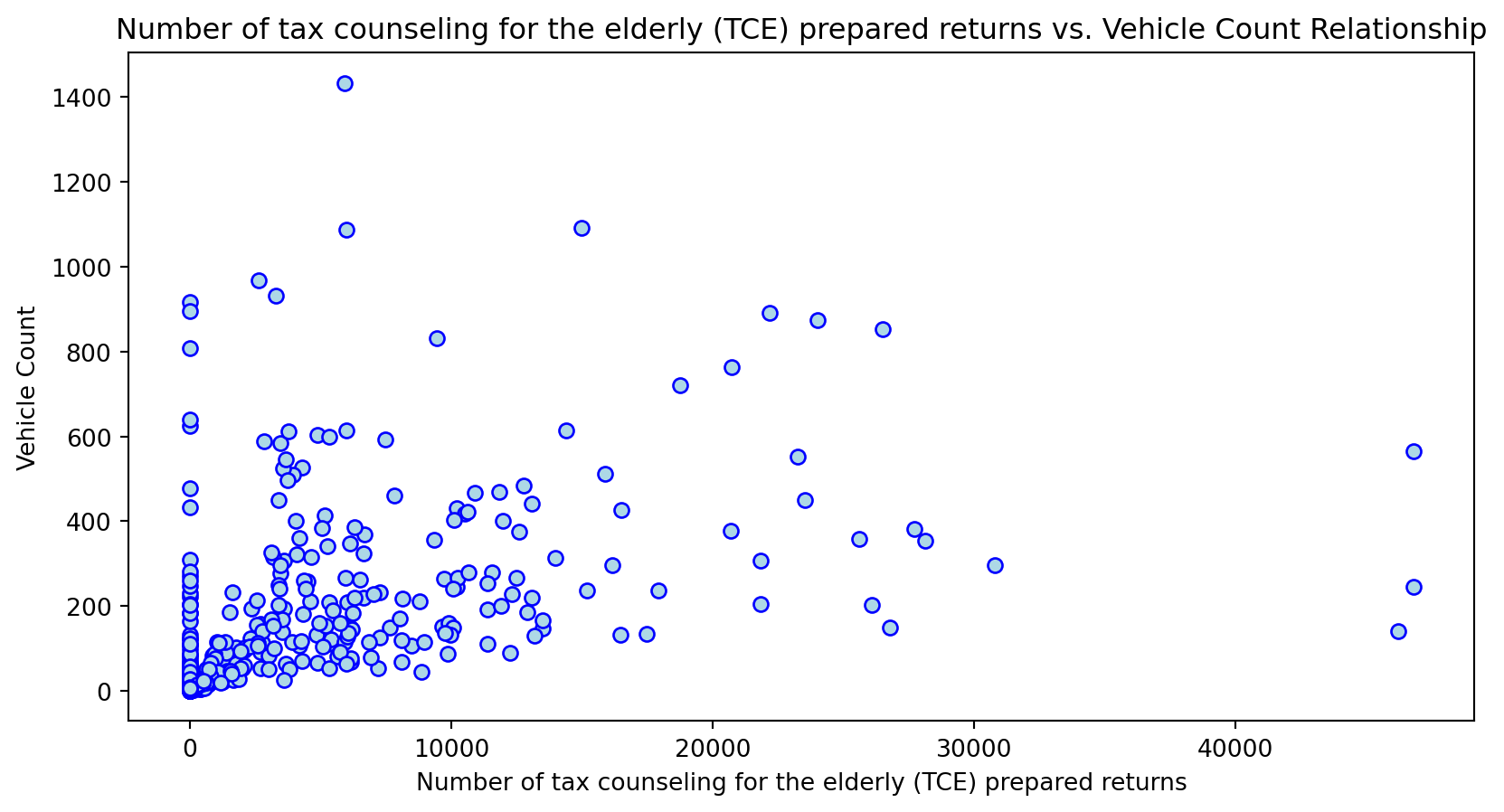
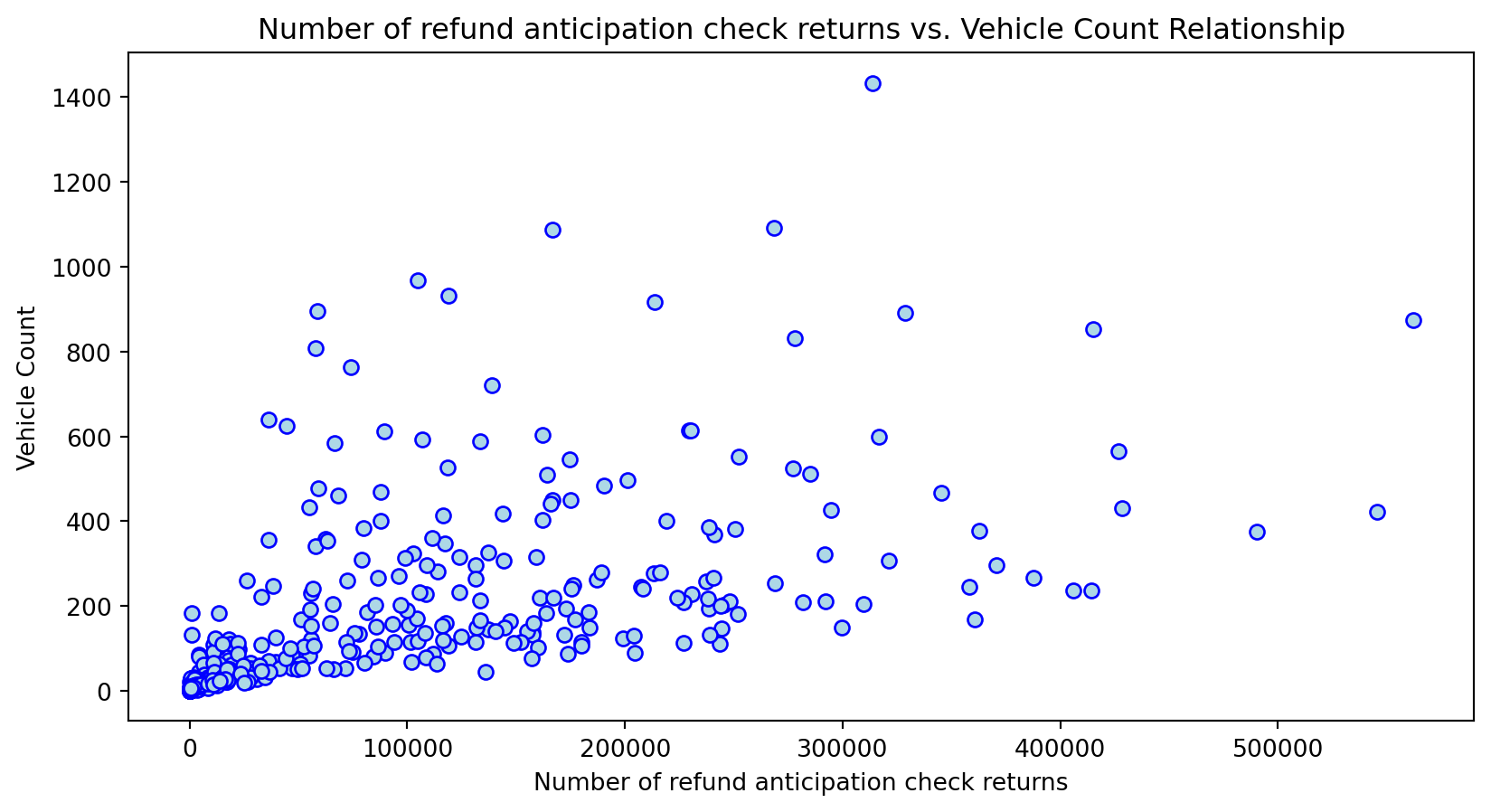
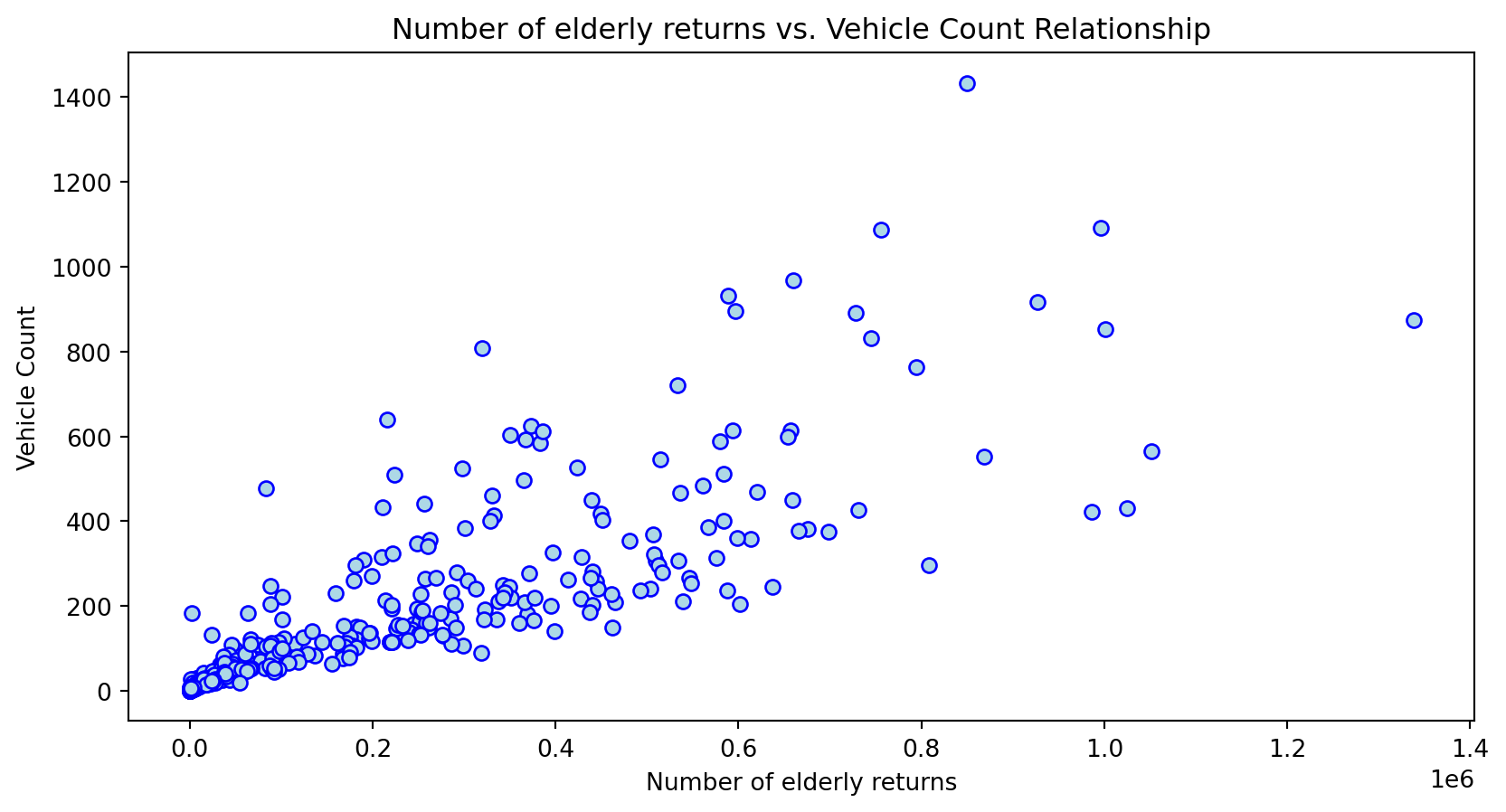
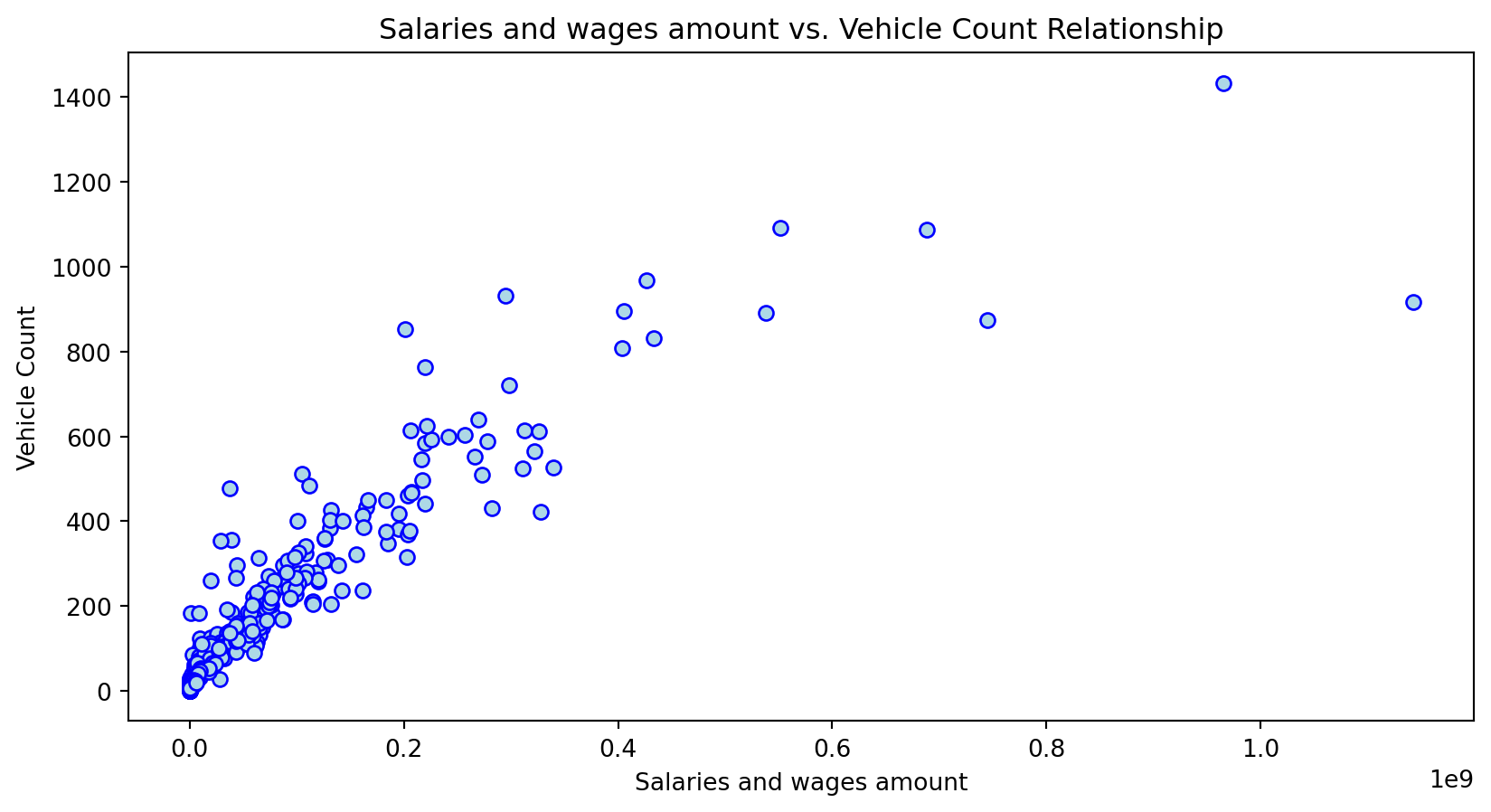


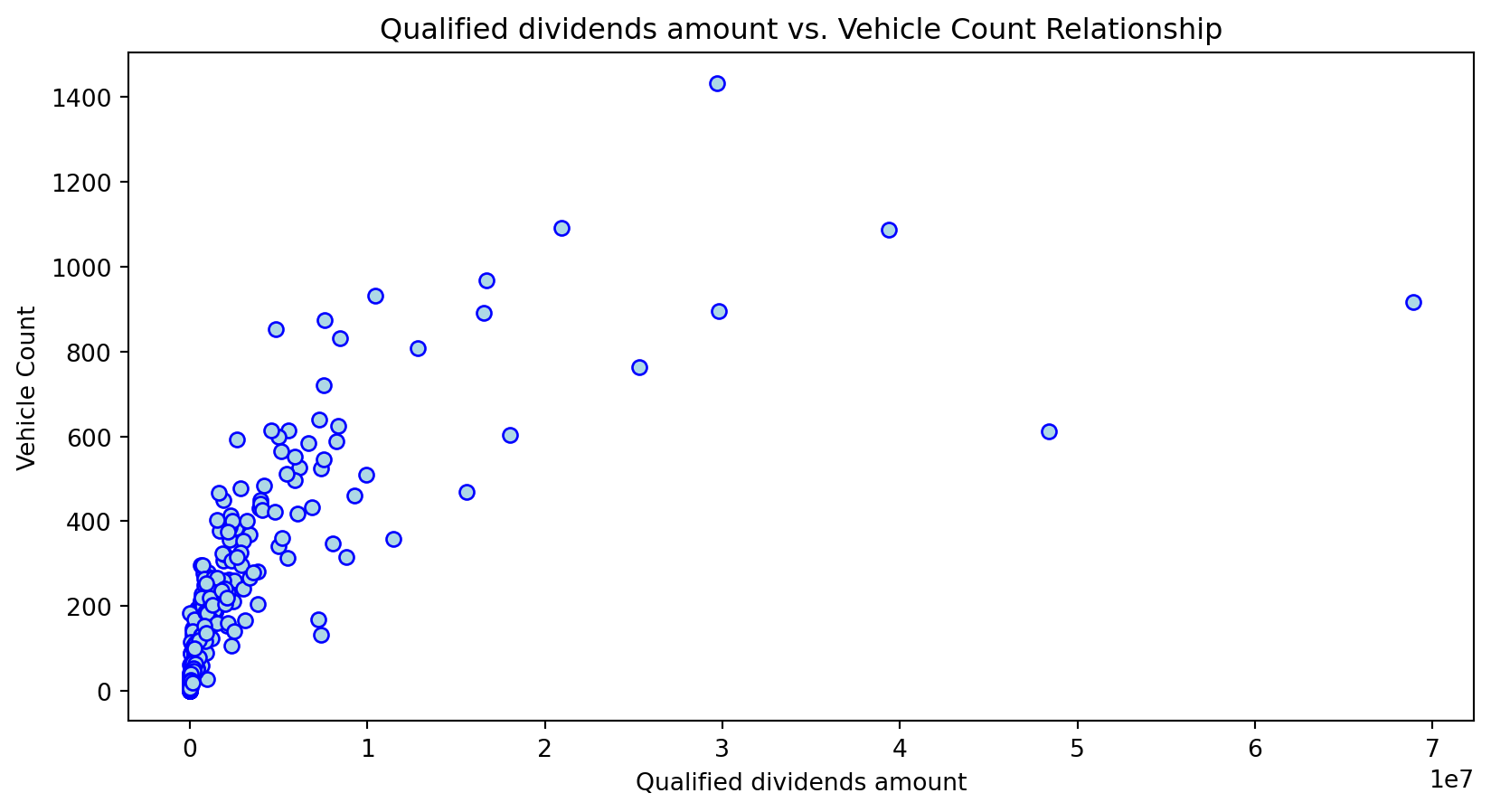
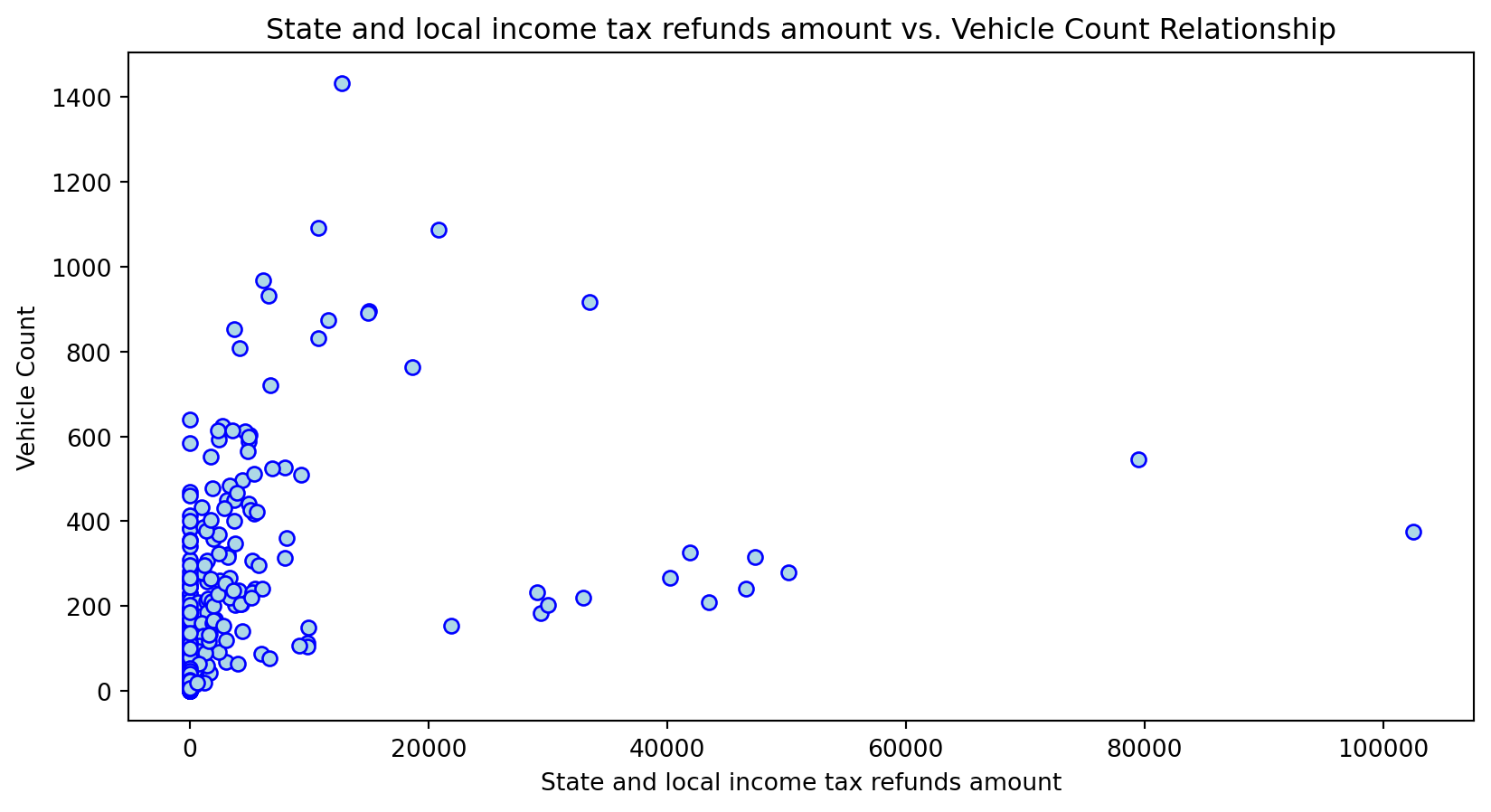
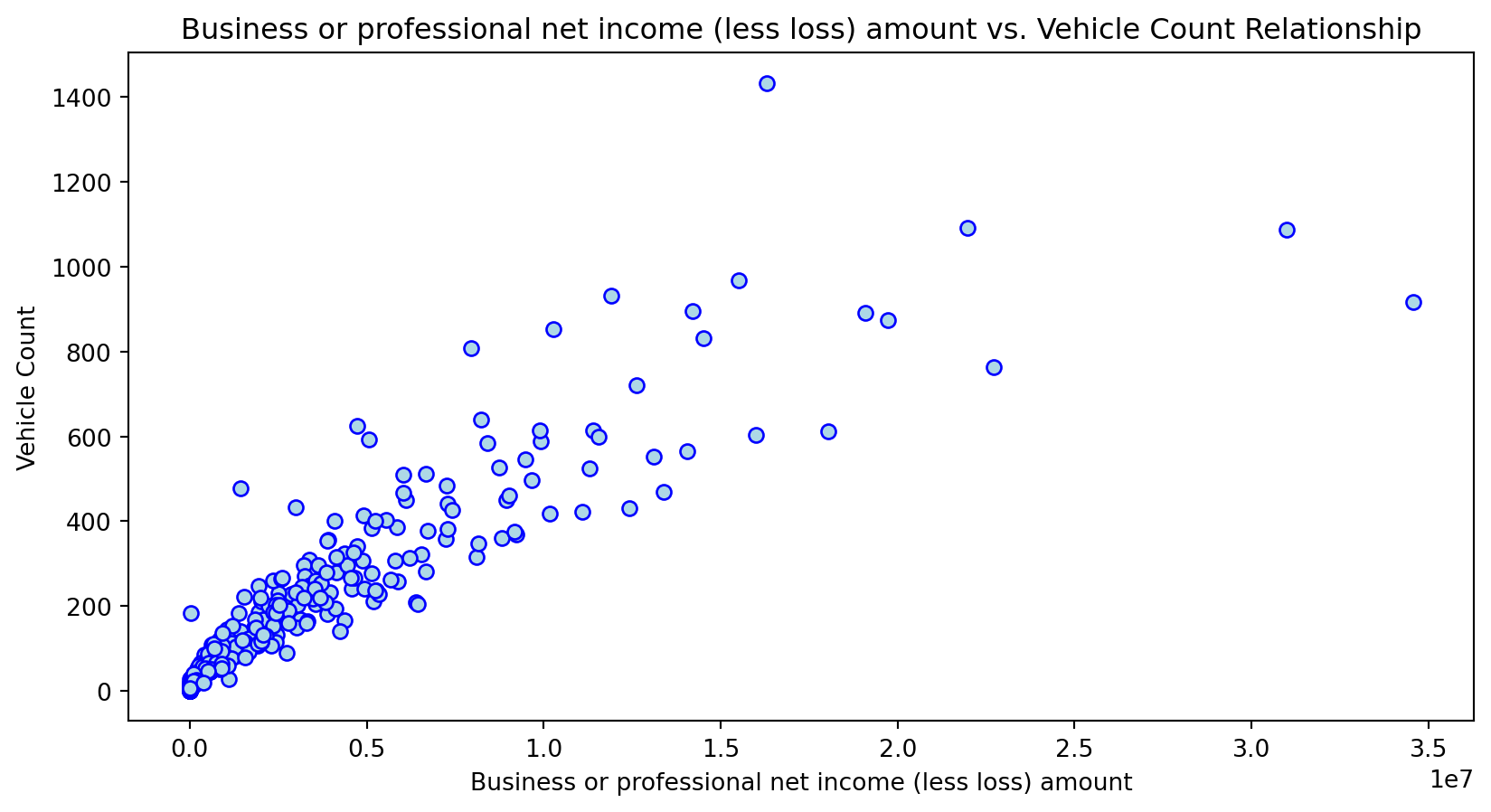
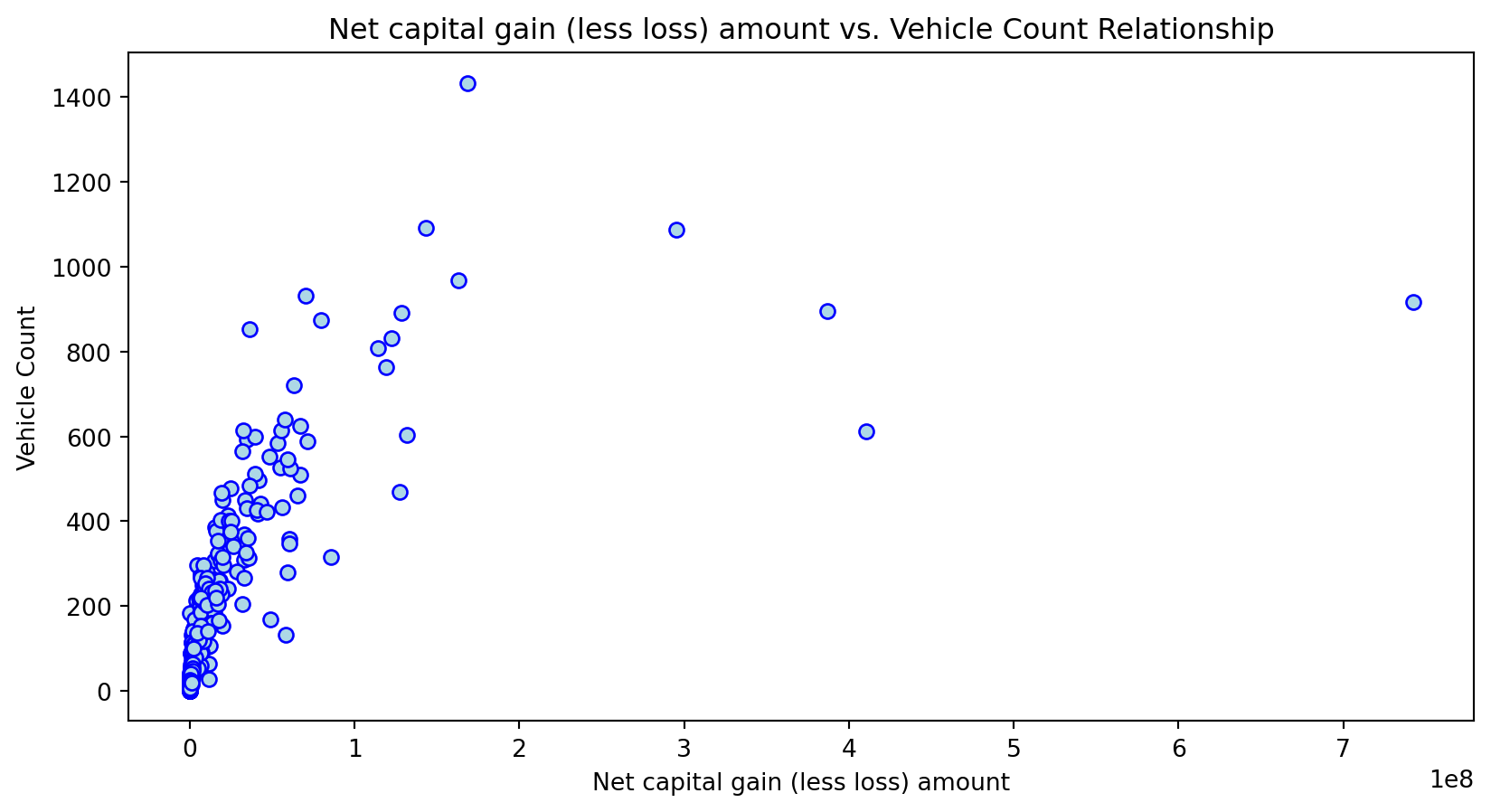
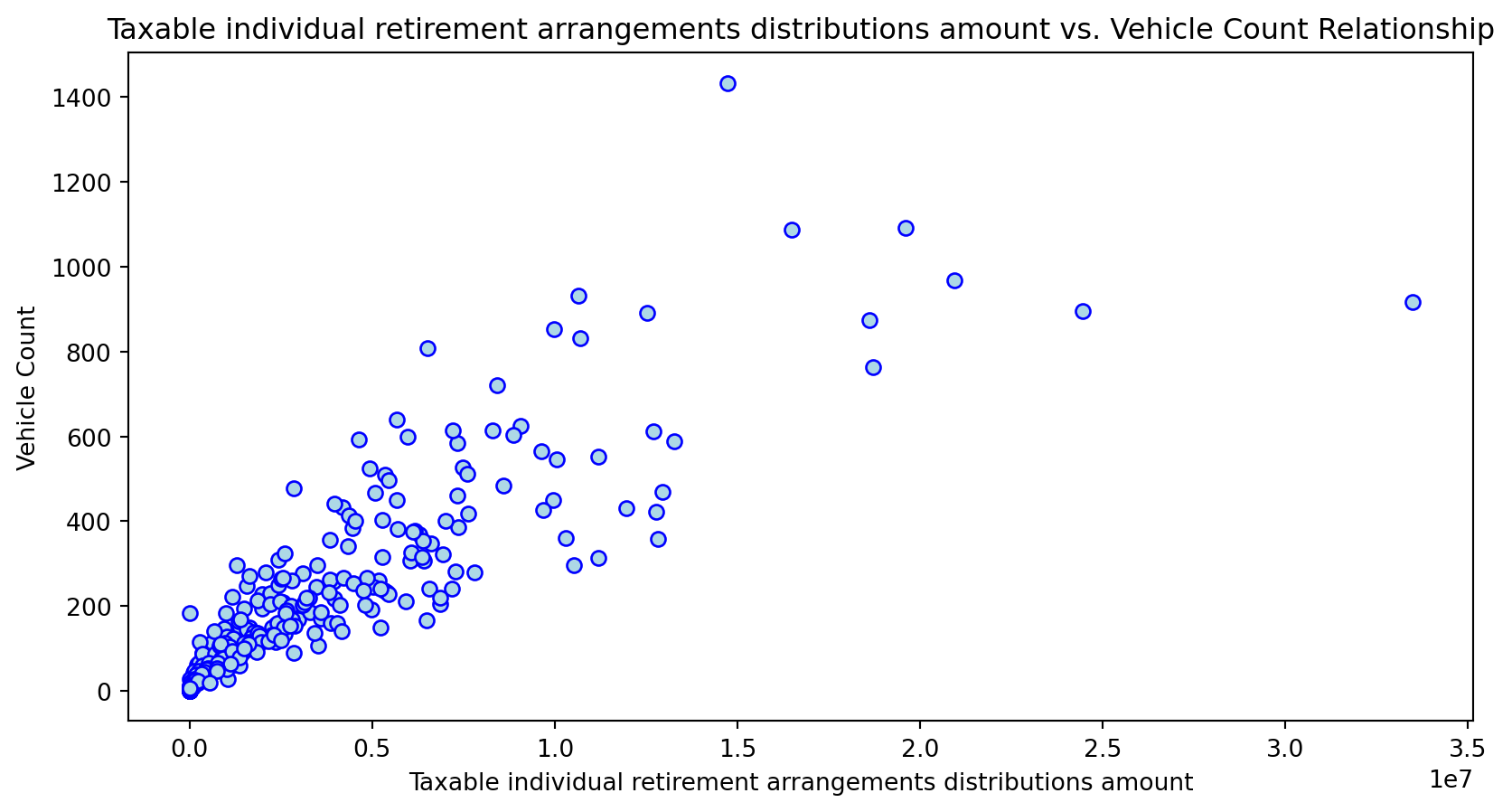

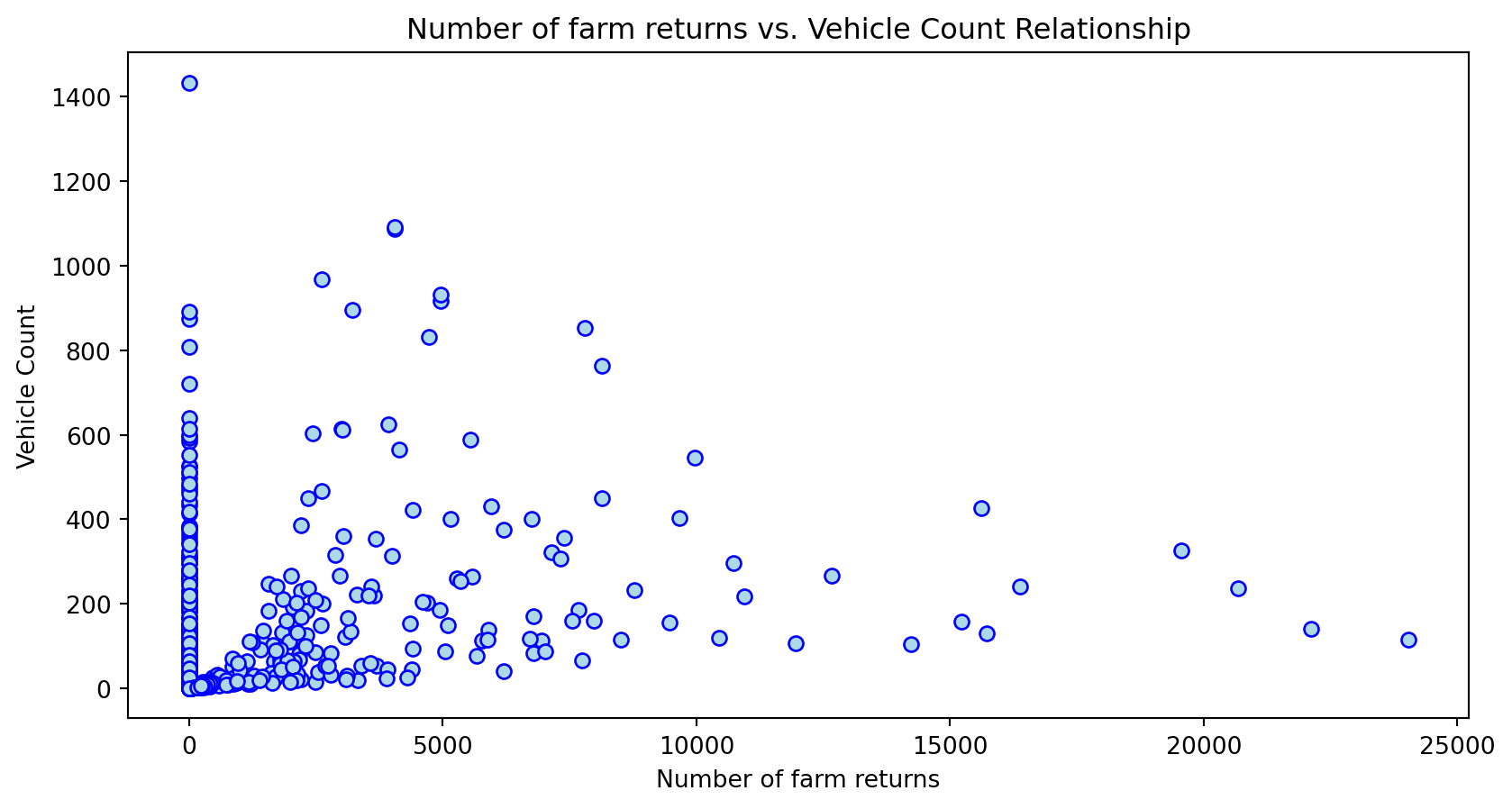
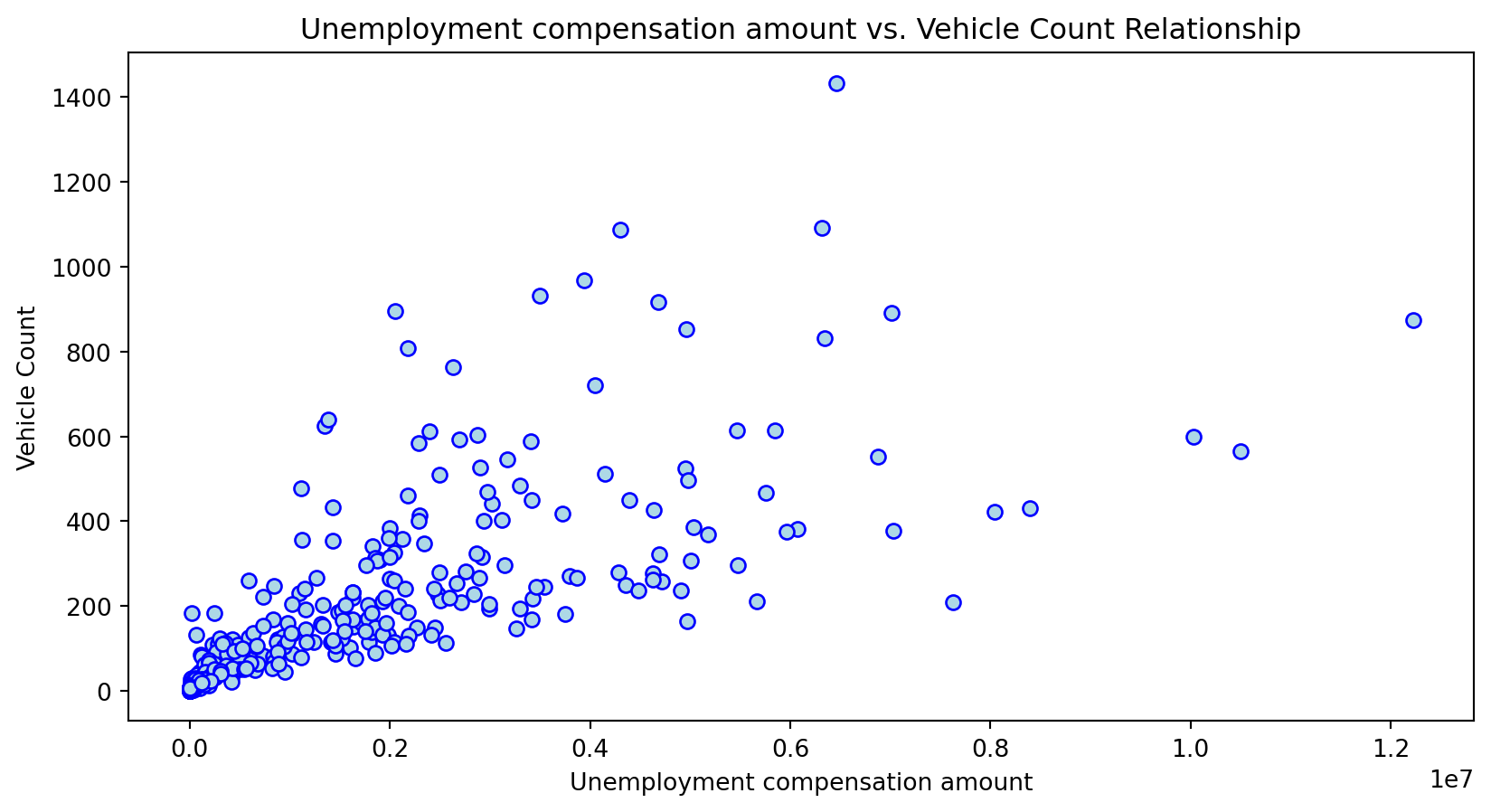
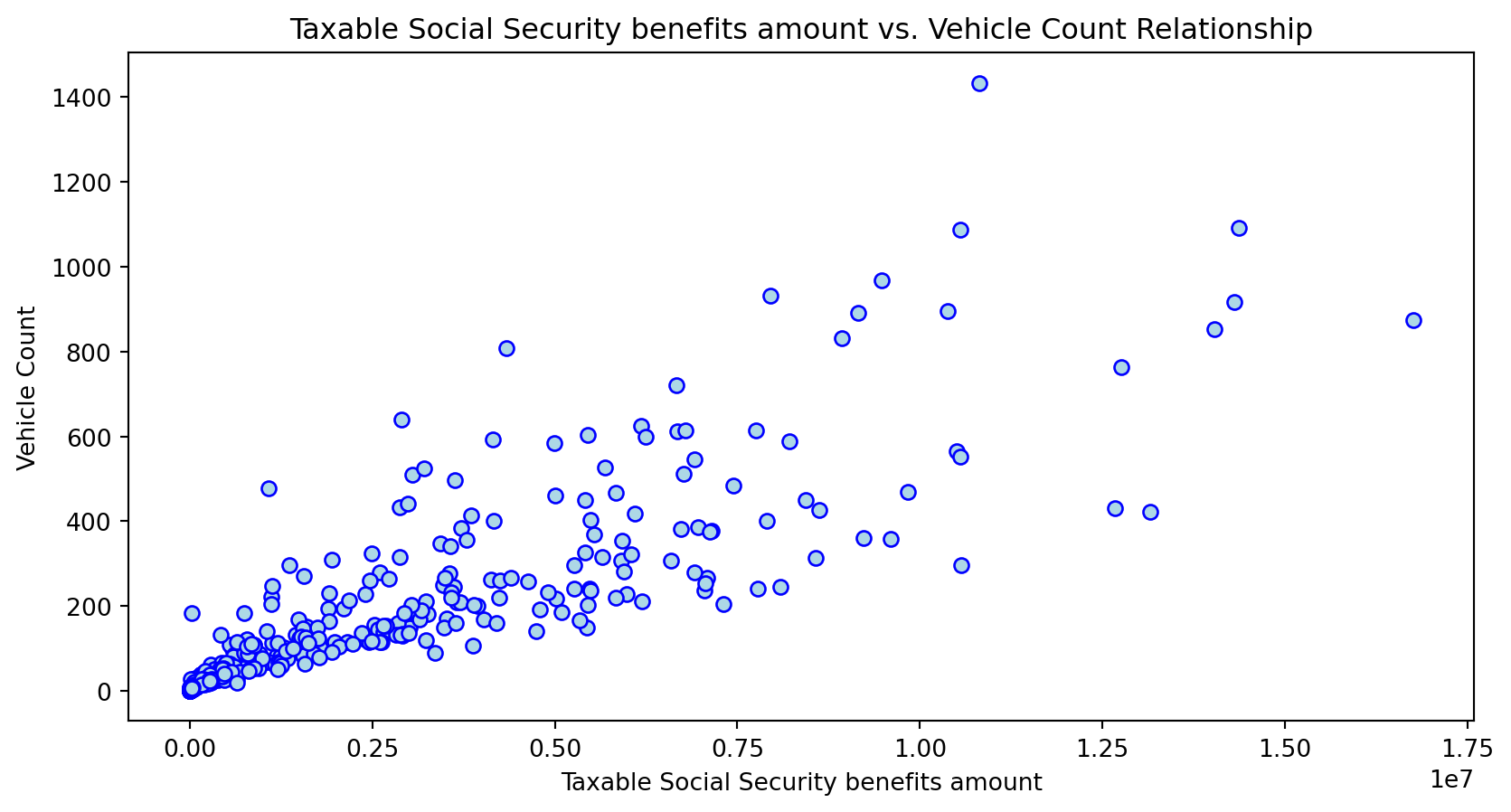

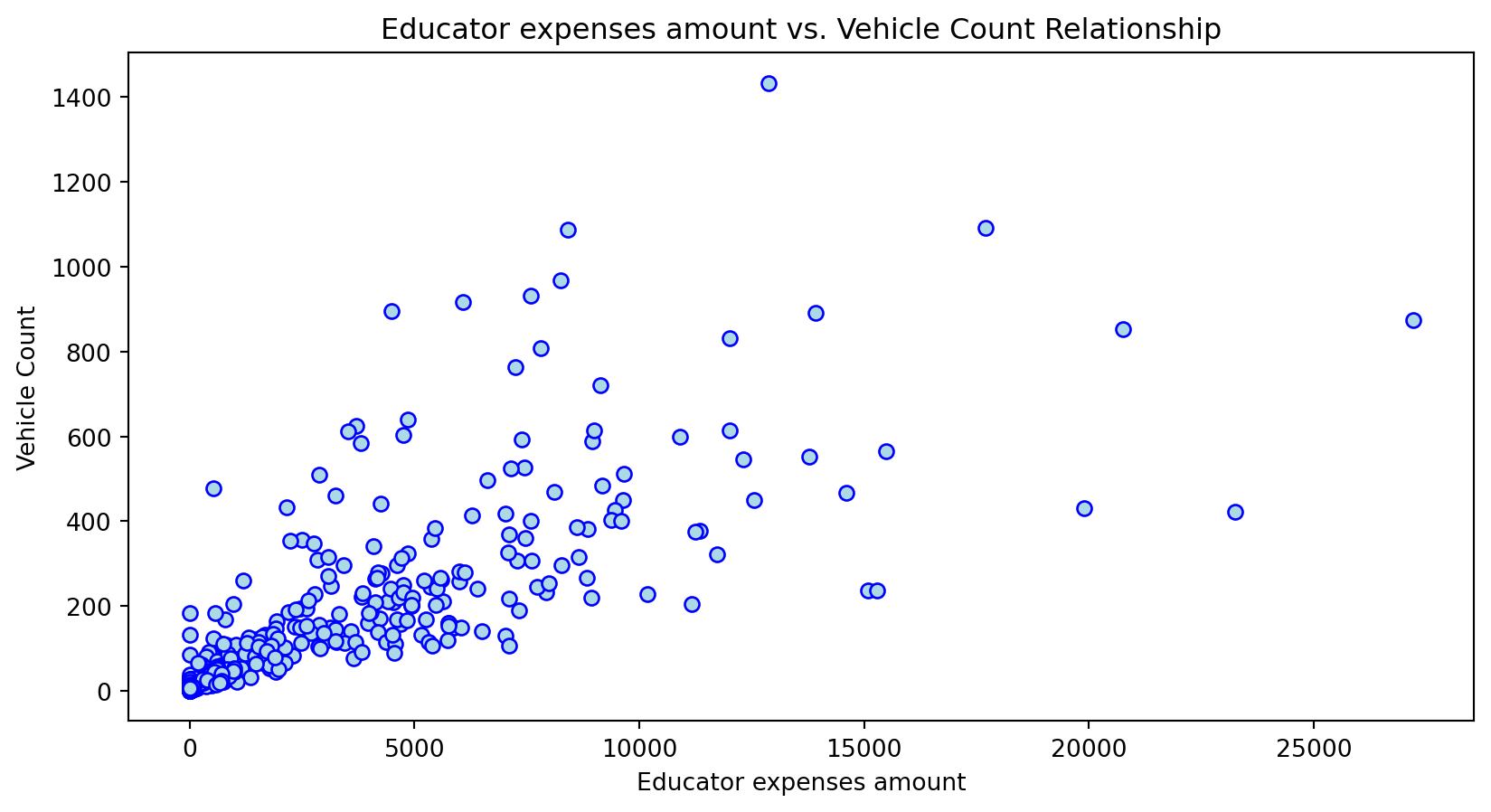




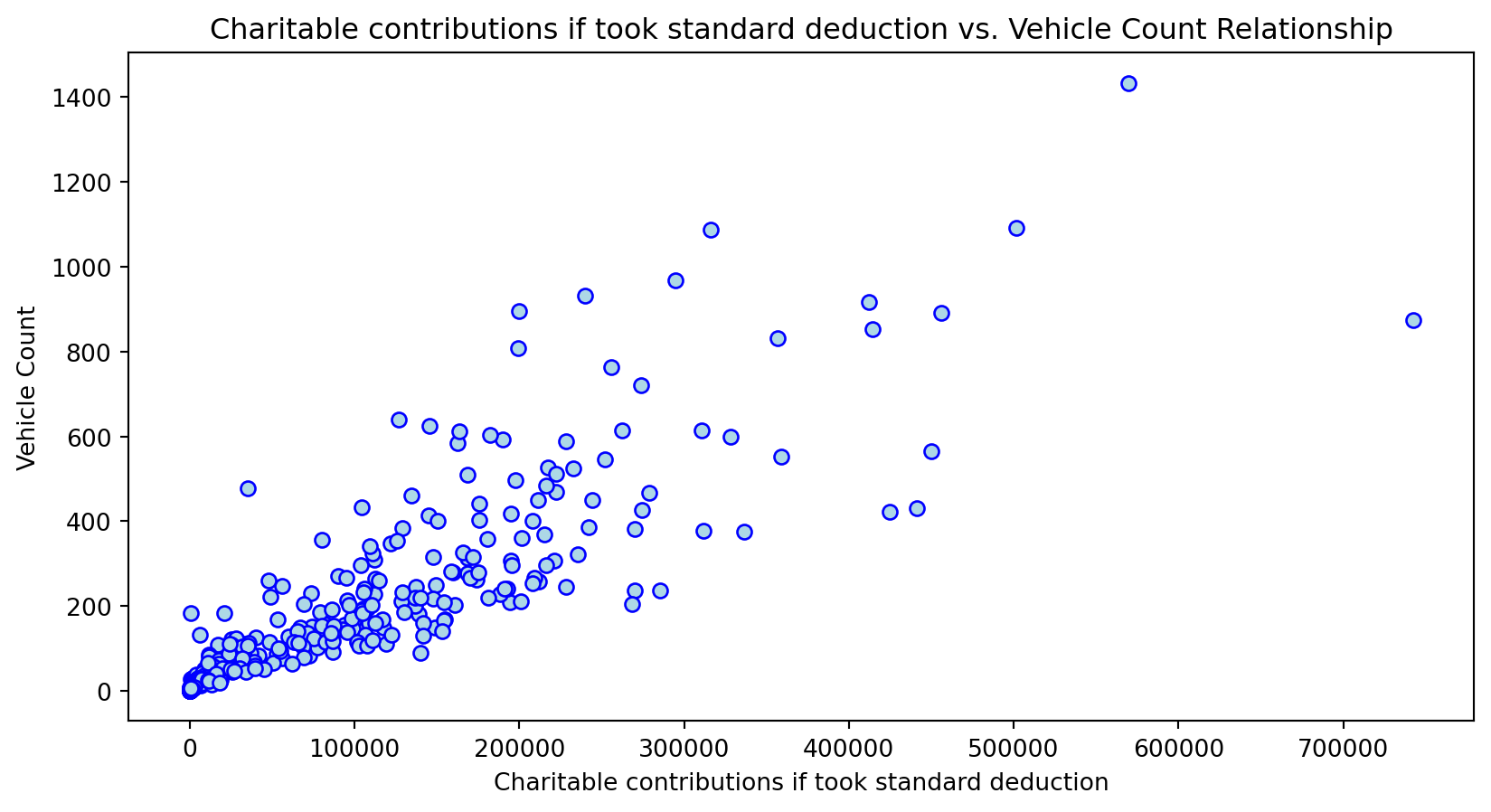





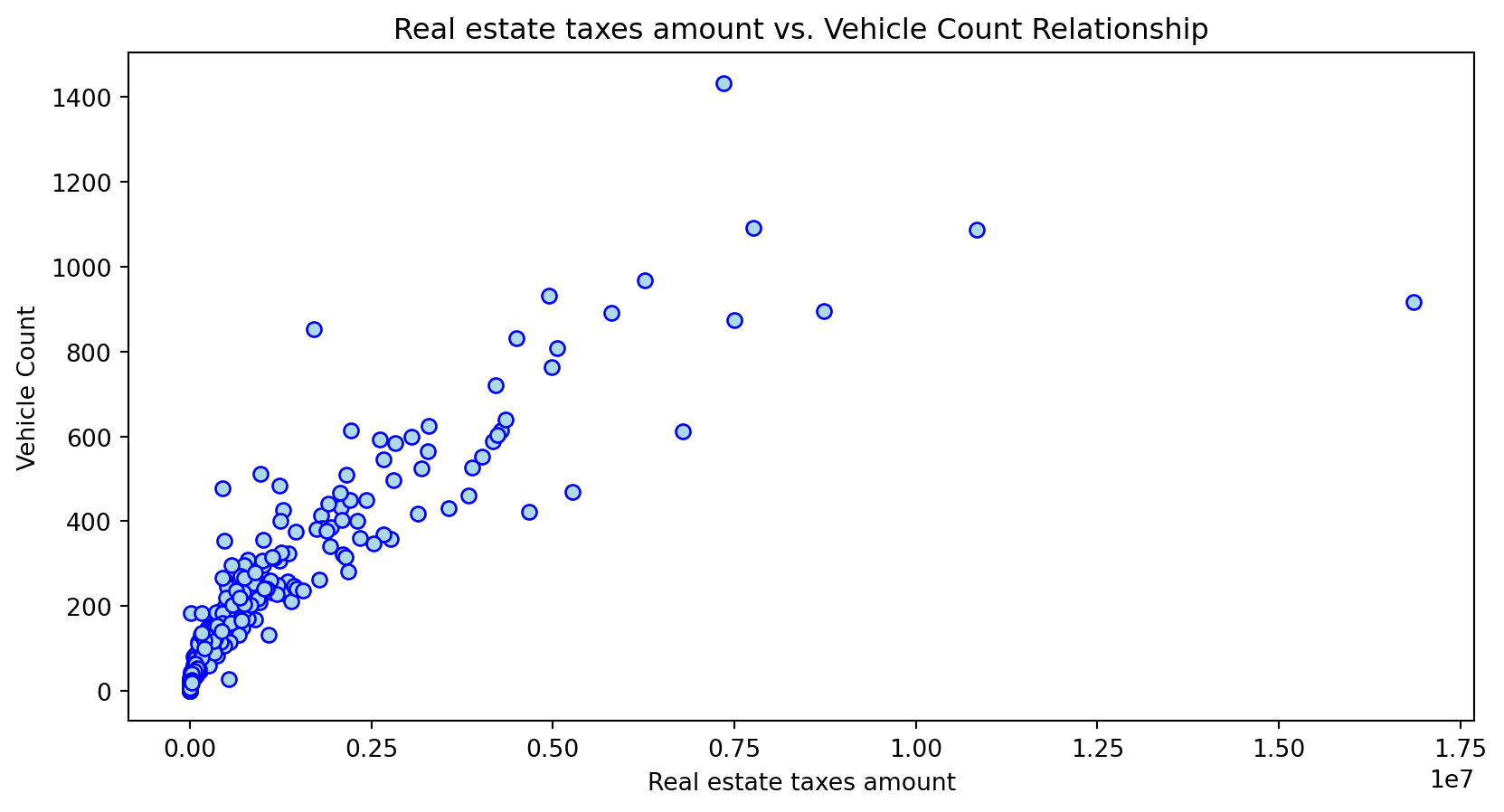
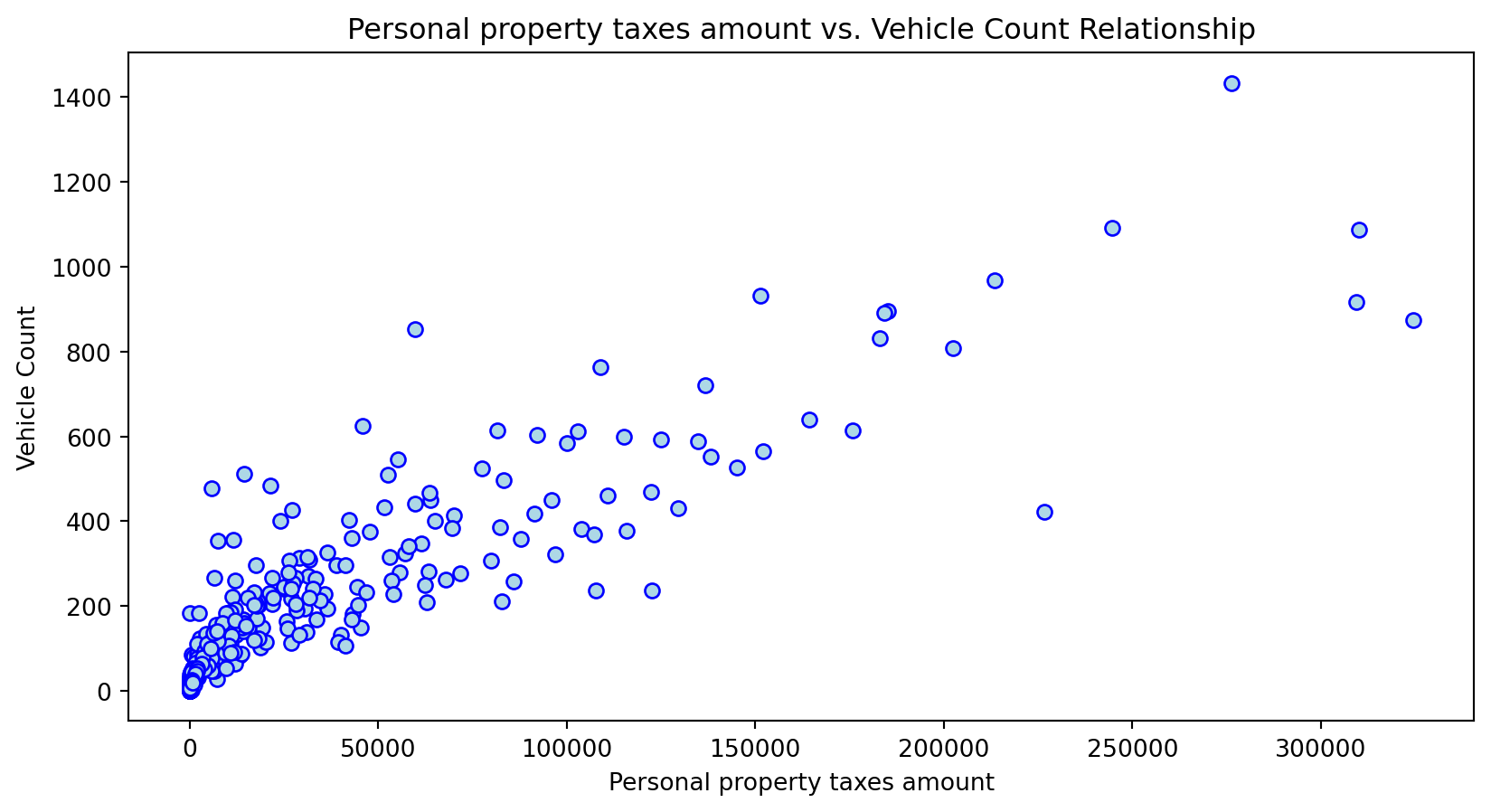
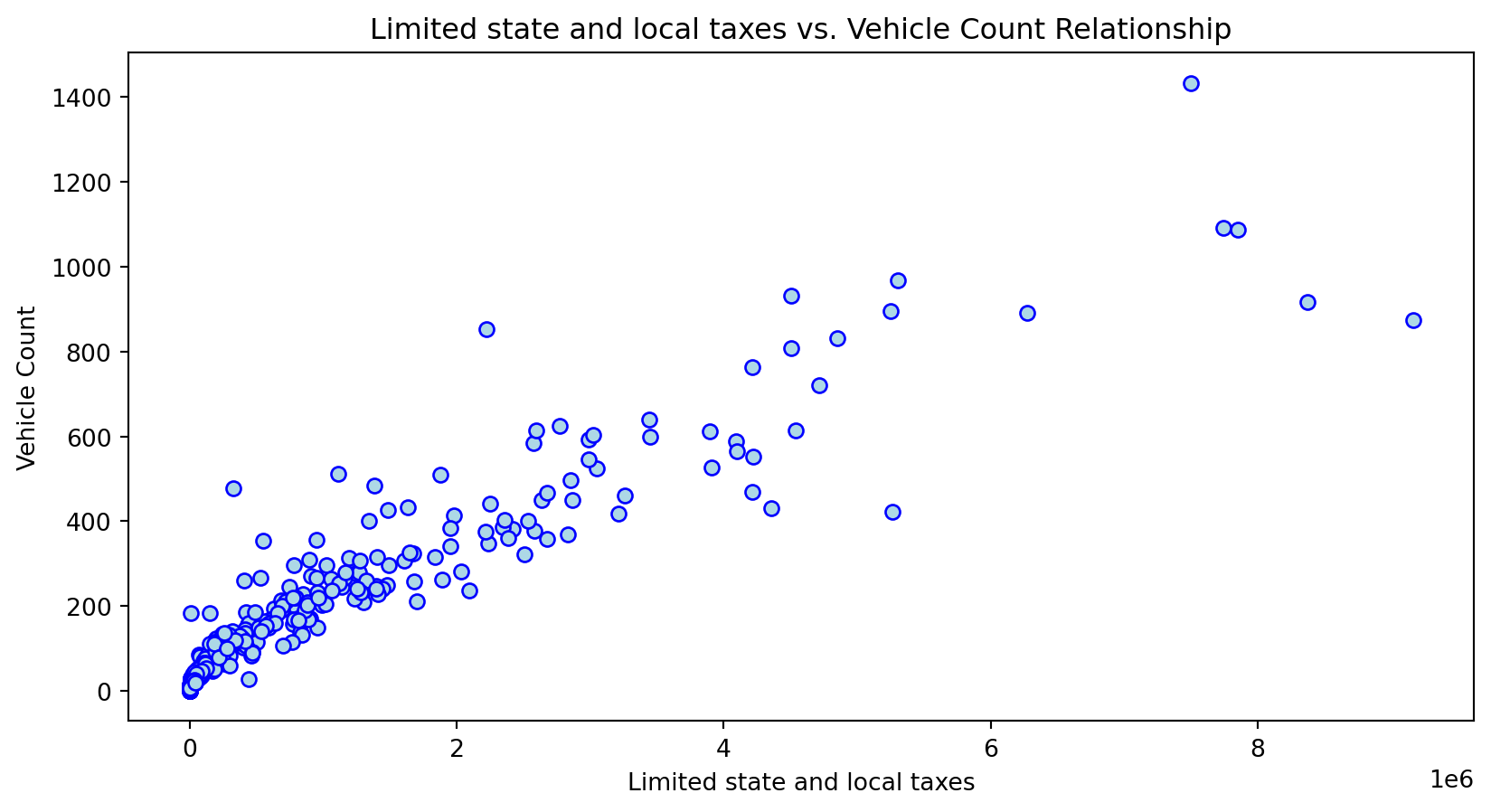
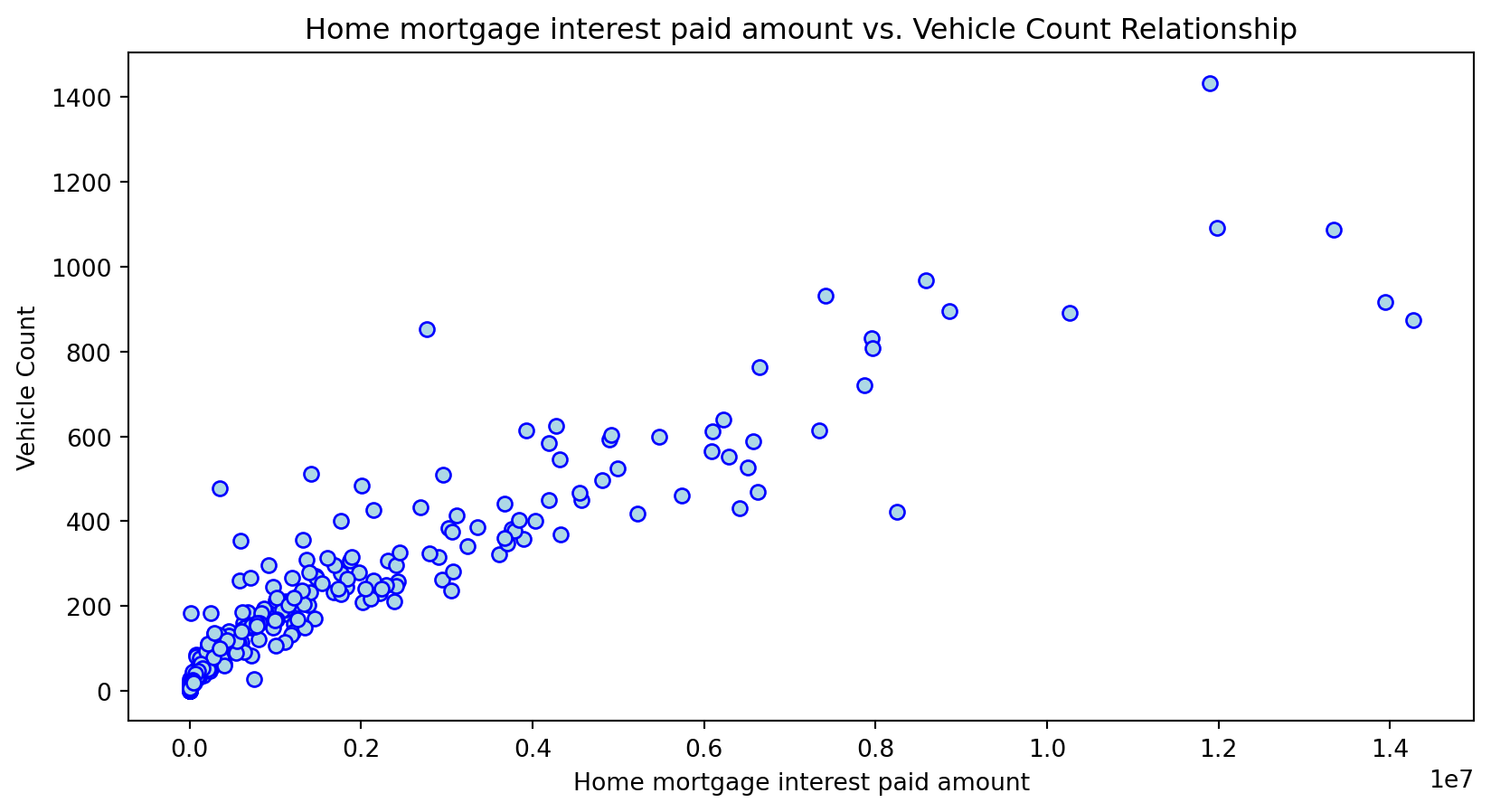
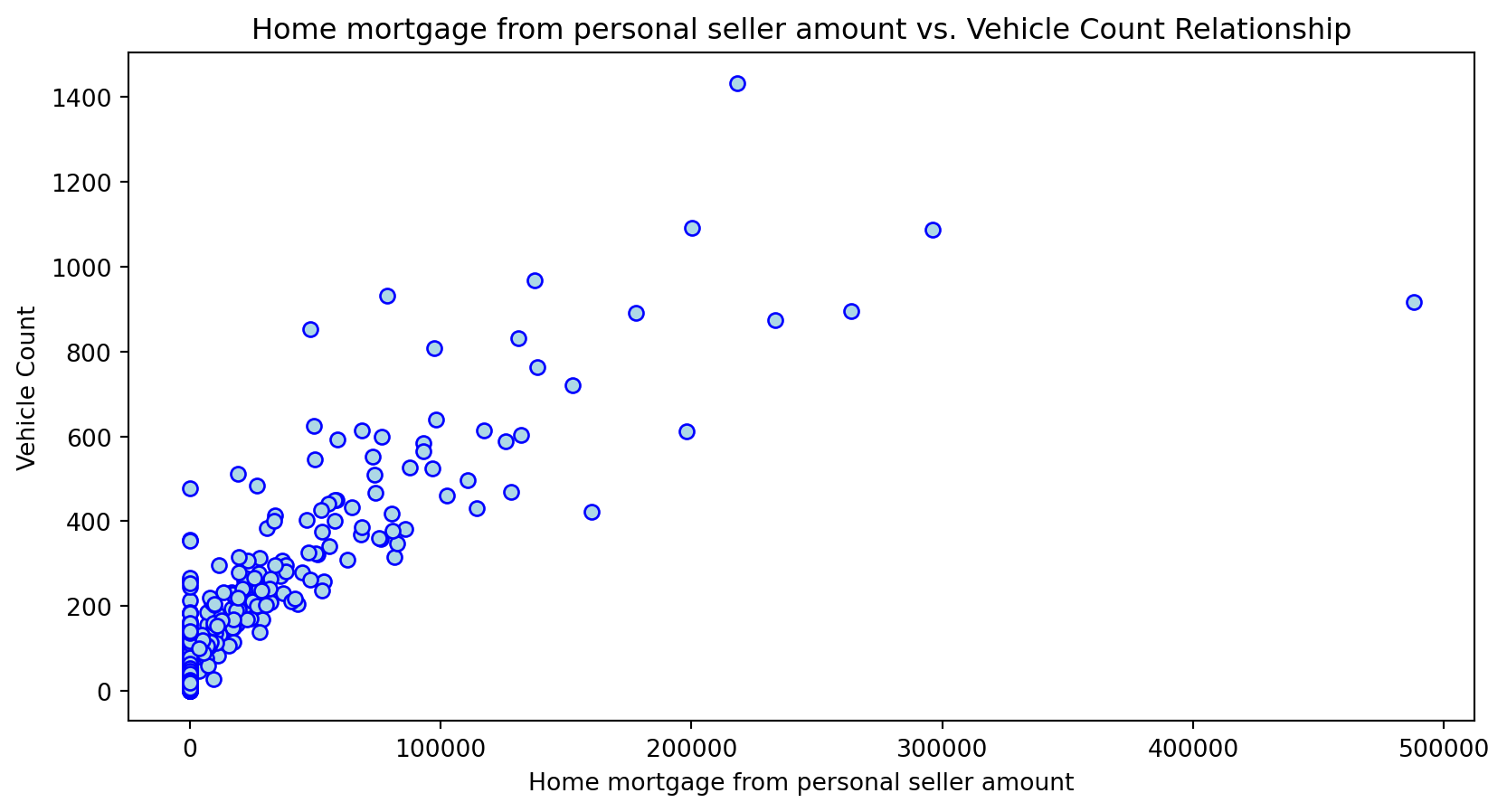


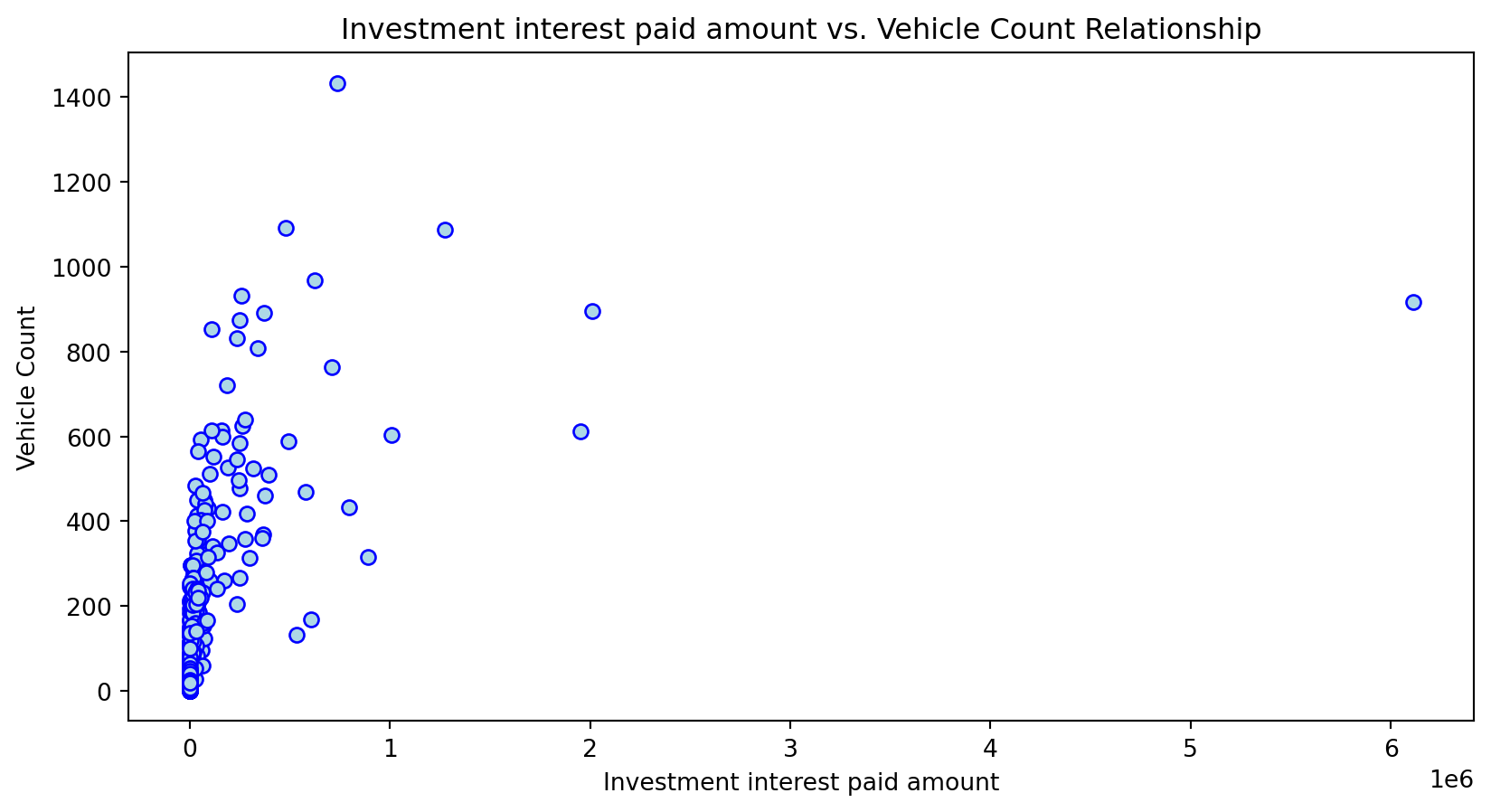
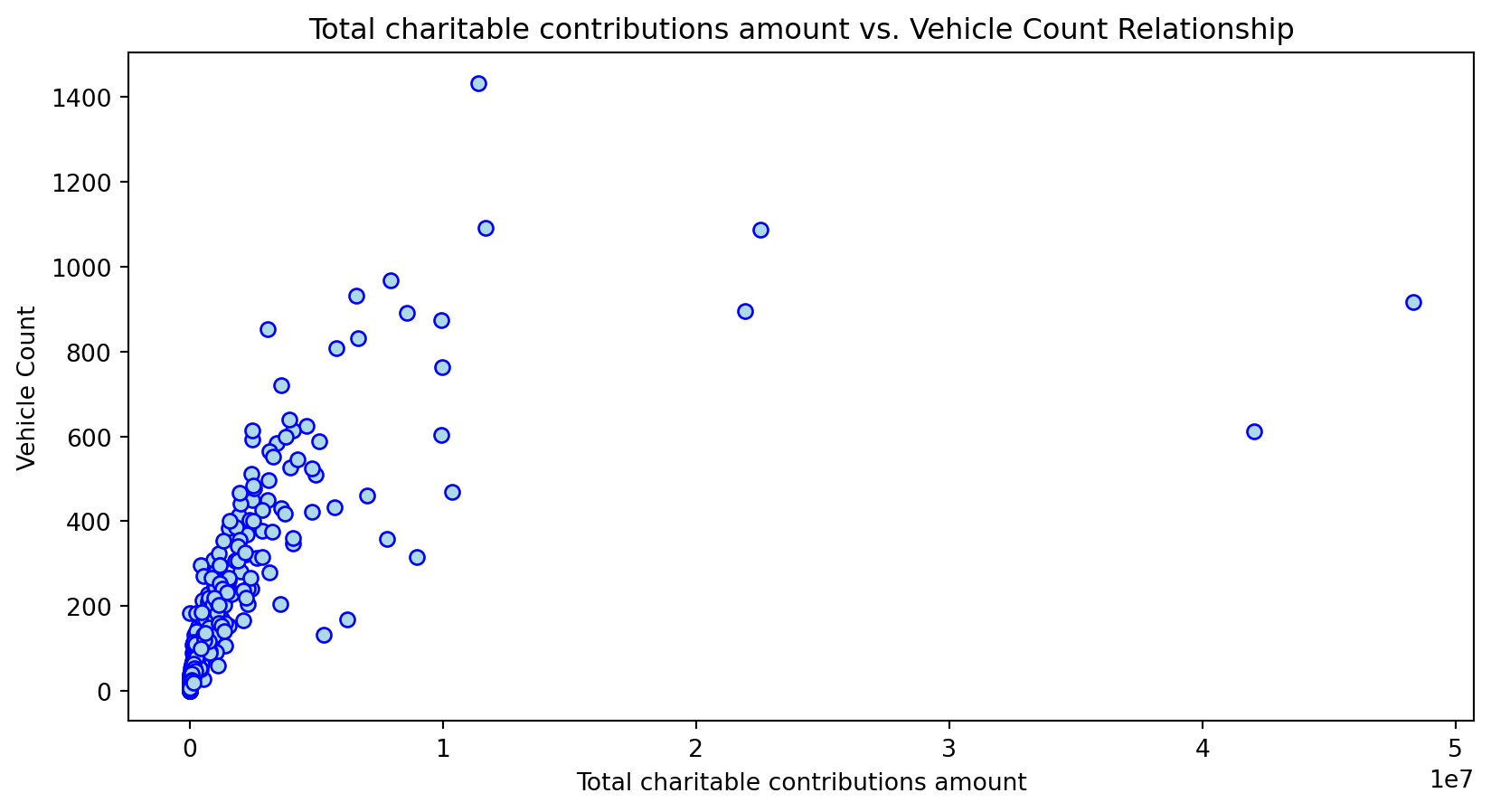


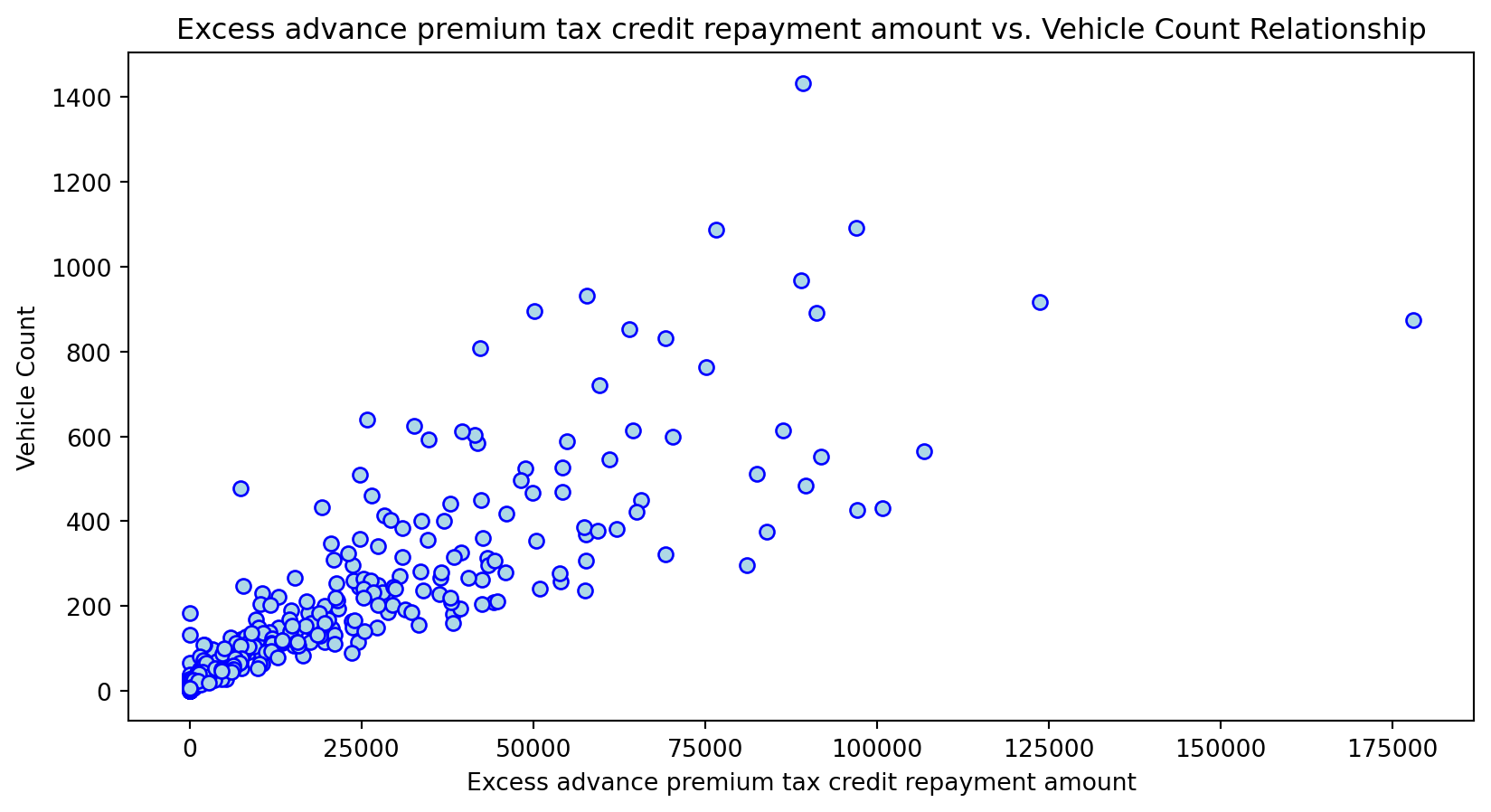





















Histogram Distributions
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
import matplotlib.pyplot as plt
import seaborn as sns
# Define a function to log transform all features
def log_transform_all_features(data):
return np.log(data)
# Impute missing values with the median and then log transform all features
def preprocess_and_log_transform_data(X):
imputer = SimpleImputer(strategy='median')
X_imputed = imputer.fit_transform(X)
X_imputed_df = pd.DataFrame(X_imputed, columns=X.columns)
X_transformed = log_transform_all_features(X_imputed_df)
return X_transformed
# Preprocess and log transform the training and test datasets
X_transformed = preprocess_and_log_transform_data(X_grouped)
# Plot histogram for each feature in the transformed dataset
def plot_transformed_feature_histograms(data, data1):
for feature in data.columns:
fig, ax = plt.subplots(1, 2, figsize=(10,5))
ax1 = plt.subplot(2,1,1)
ax1 = sns.histplot(data[feature], kde=True, bins=50)
ax2 = plt.subplot(2,1,2)
ax2 = sns.histplot(data1[feature], kde=True, bins=50)
ax1.title.set_text(f'Original vs. Log-Transformed: {feature}')
plt.xlabel(feature)
plt.ylabel('Frequency')
plt.grid(True)
plt.tight_layout()
plt.savefig(f'../../results/figures/histograms/{feature}_histogram.png')
plt.show()
# Plot the histograms for the log-transformed features
plot_transformed_feature_histograms(X_grouped, X_transformed)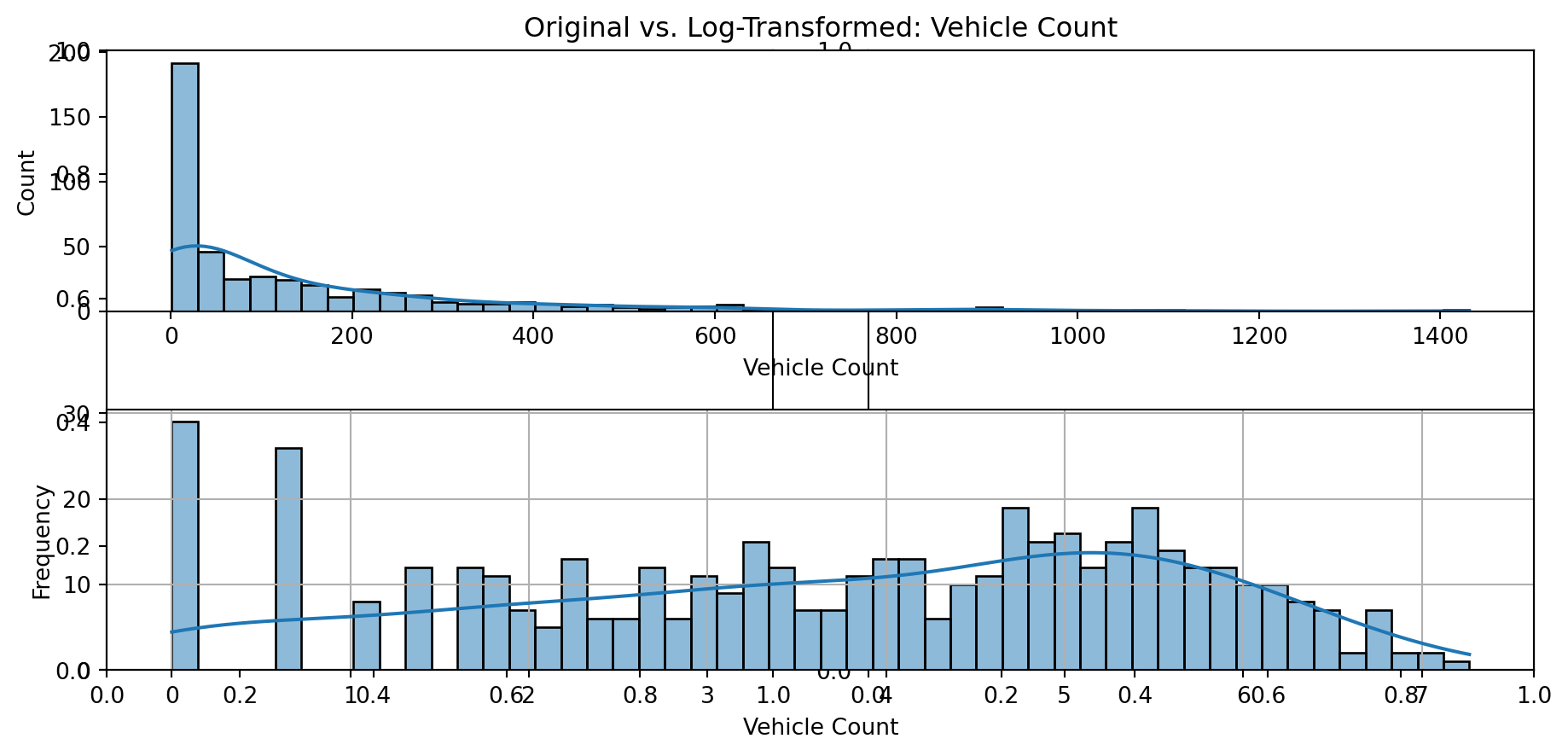
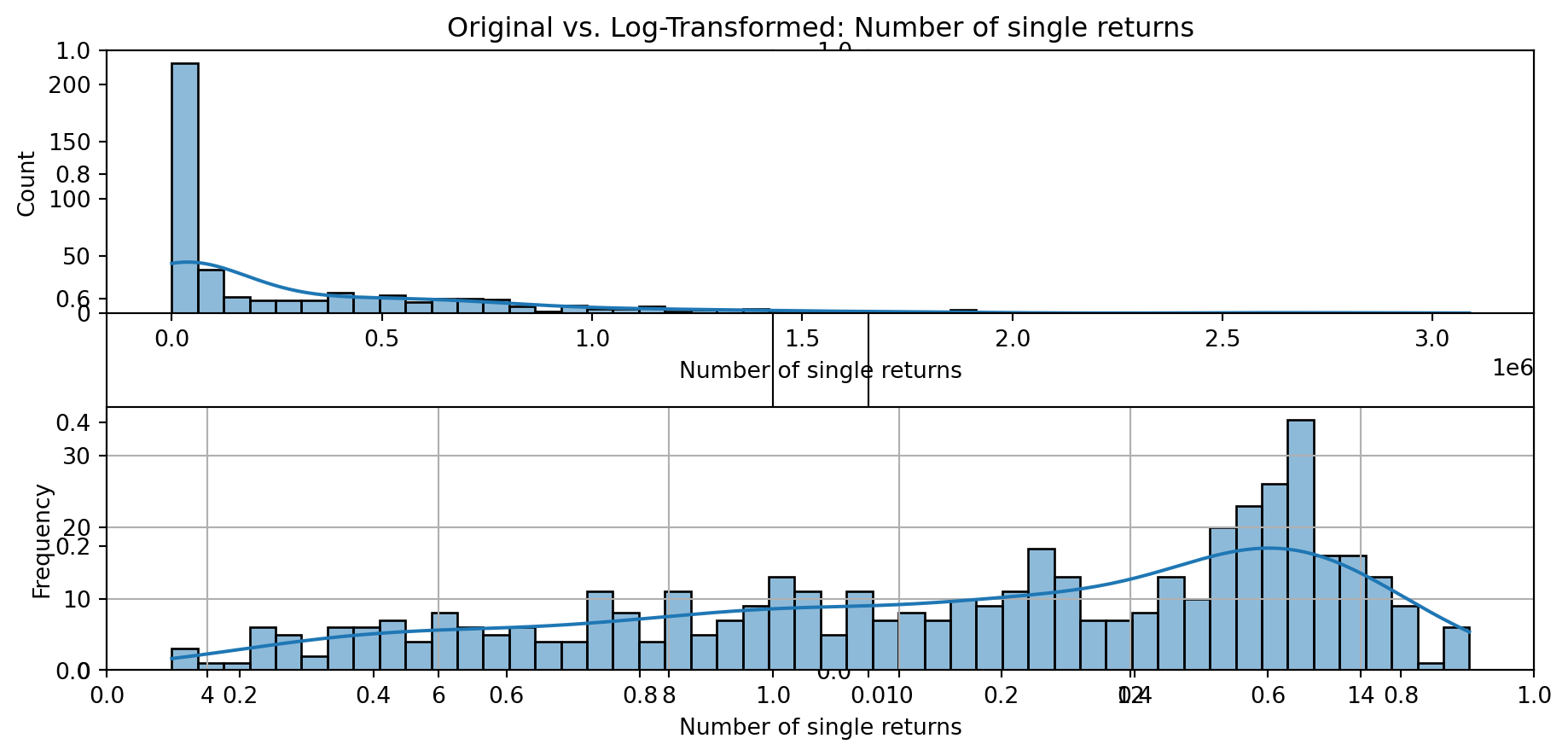
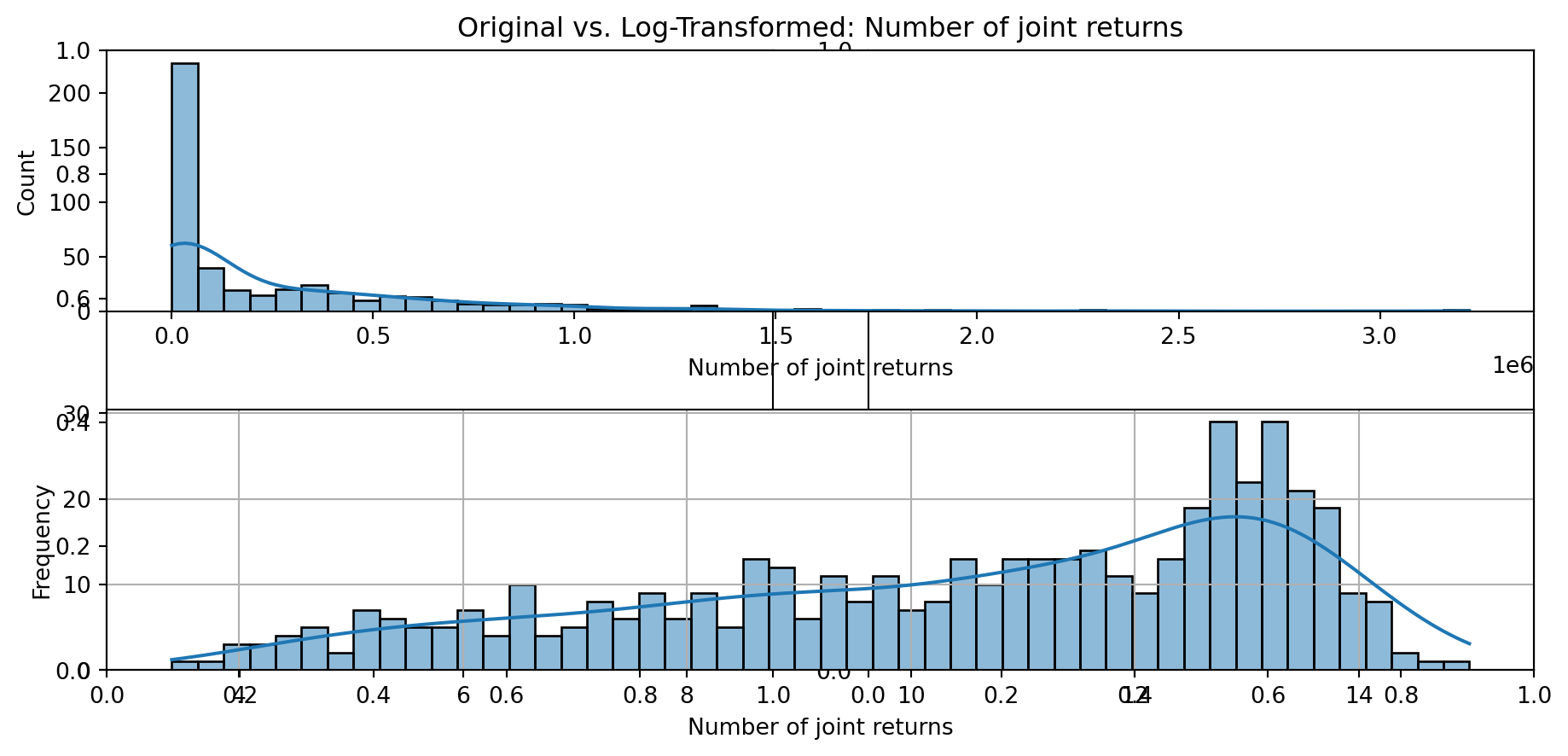
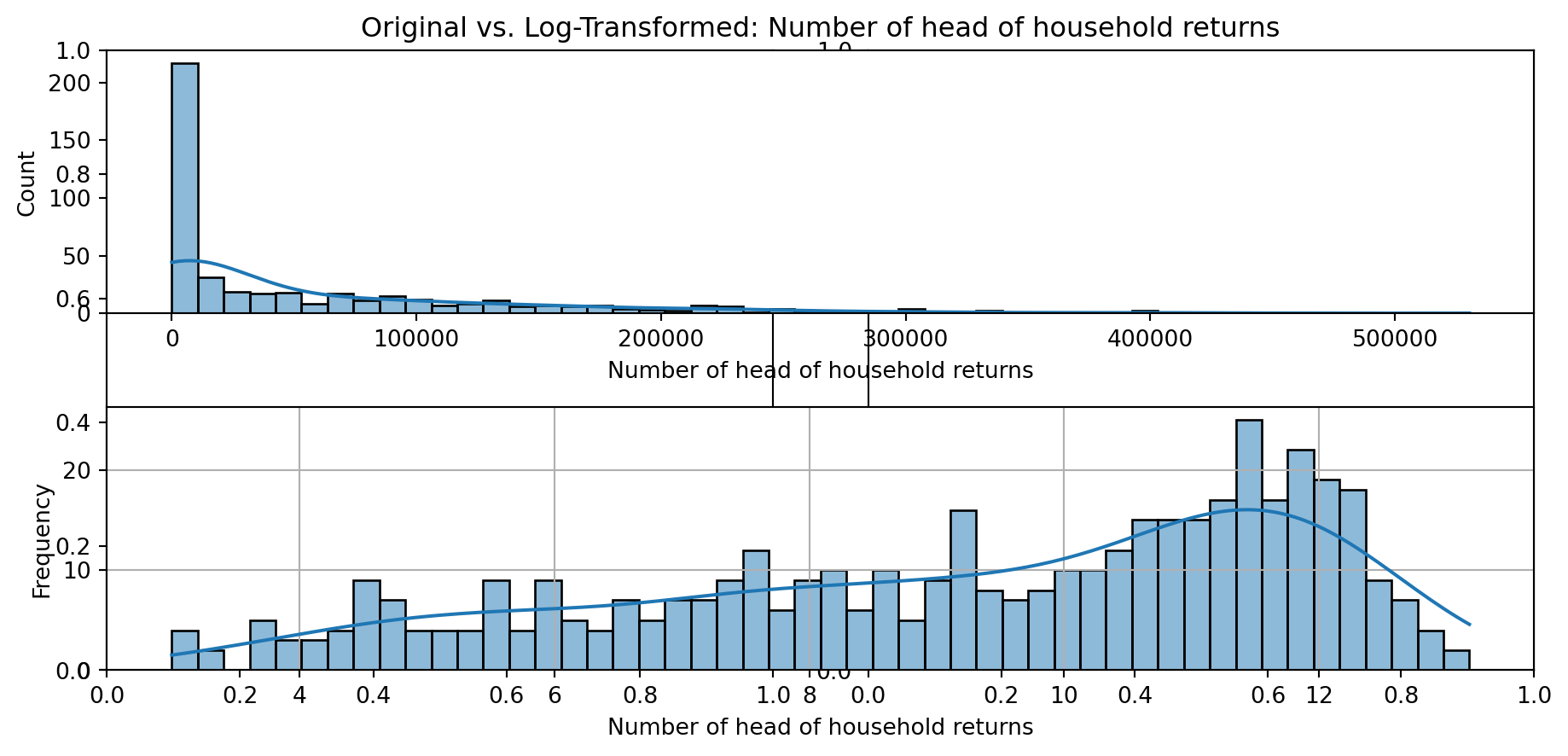
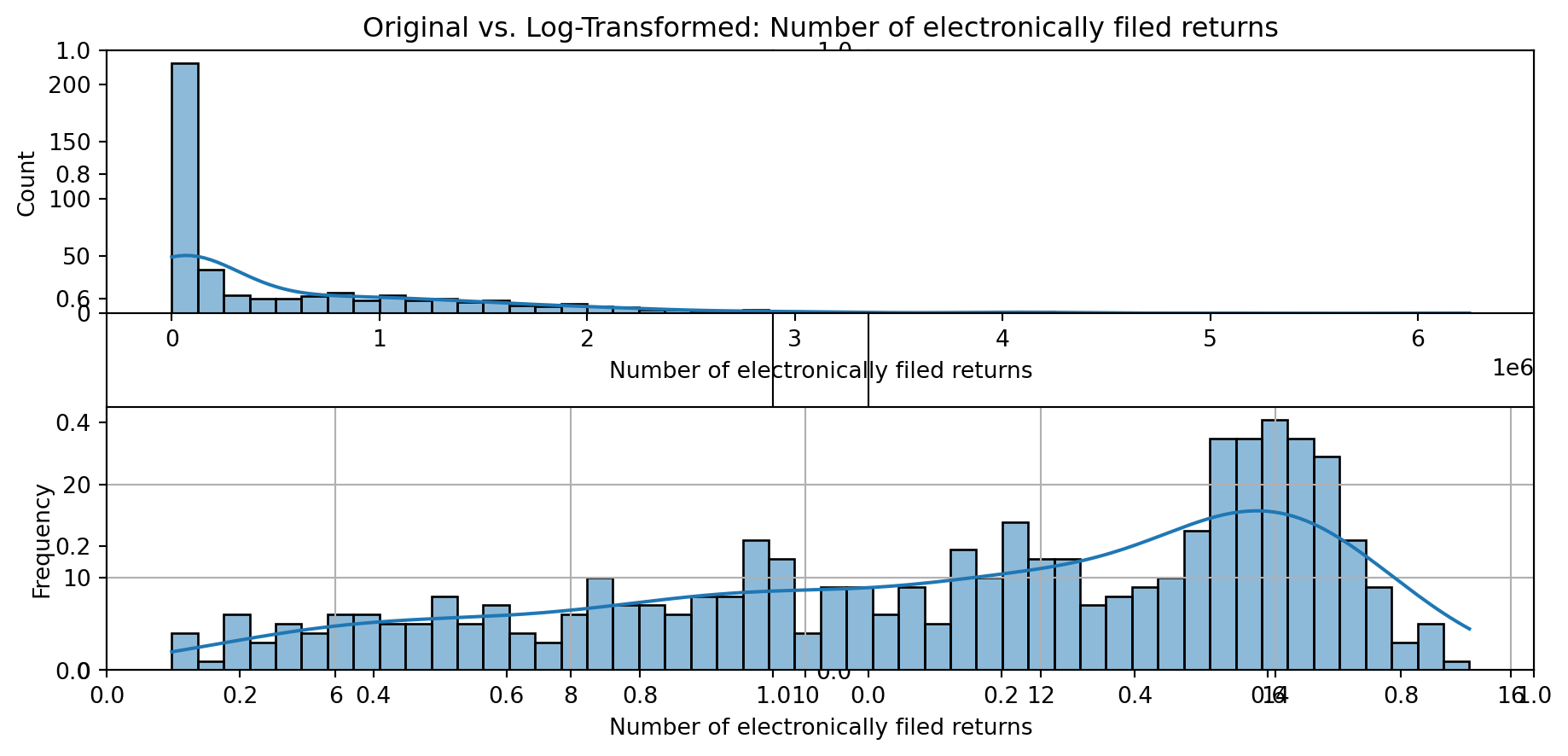
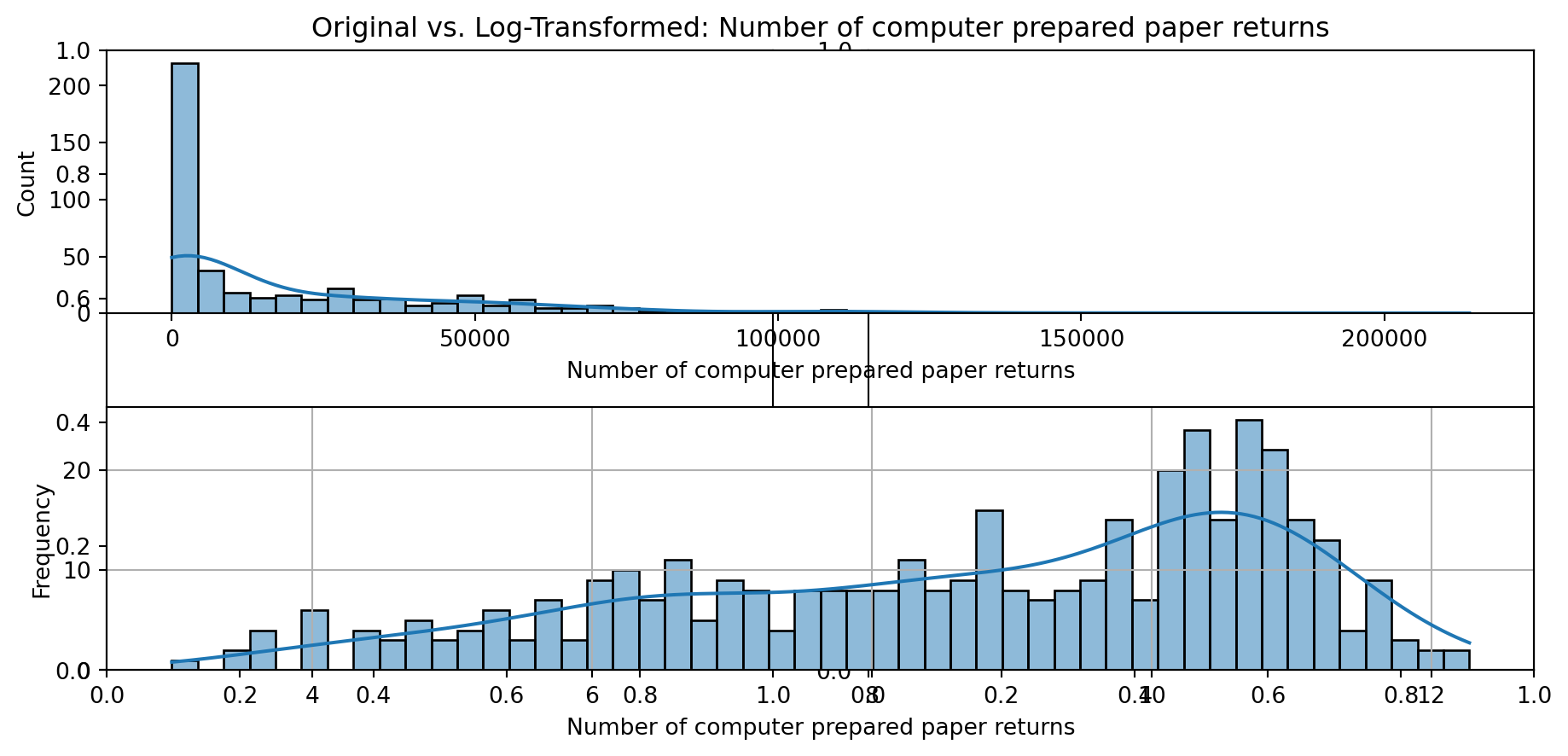
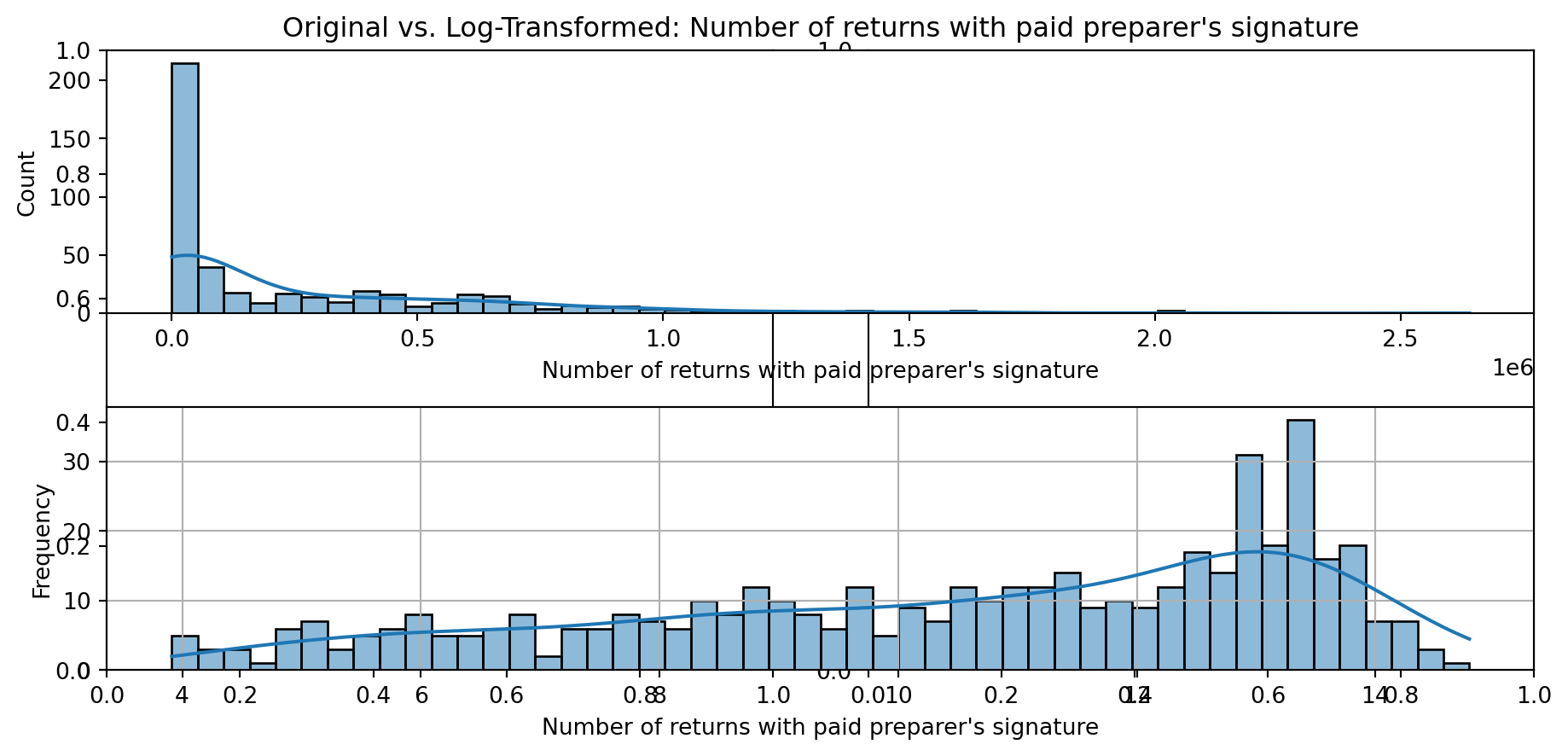
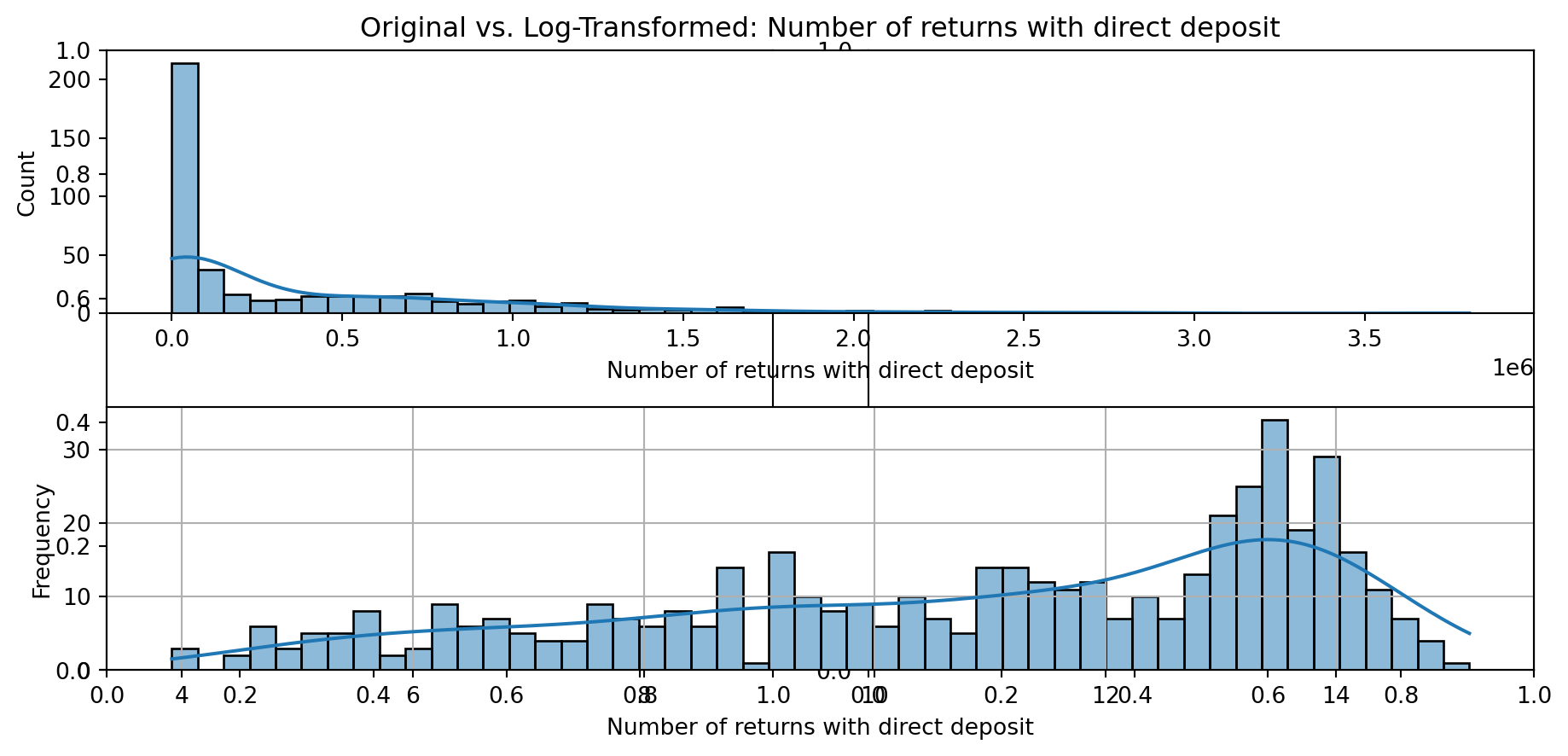
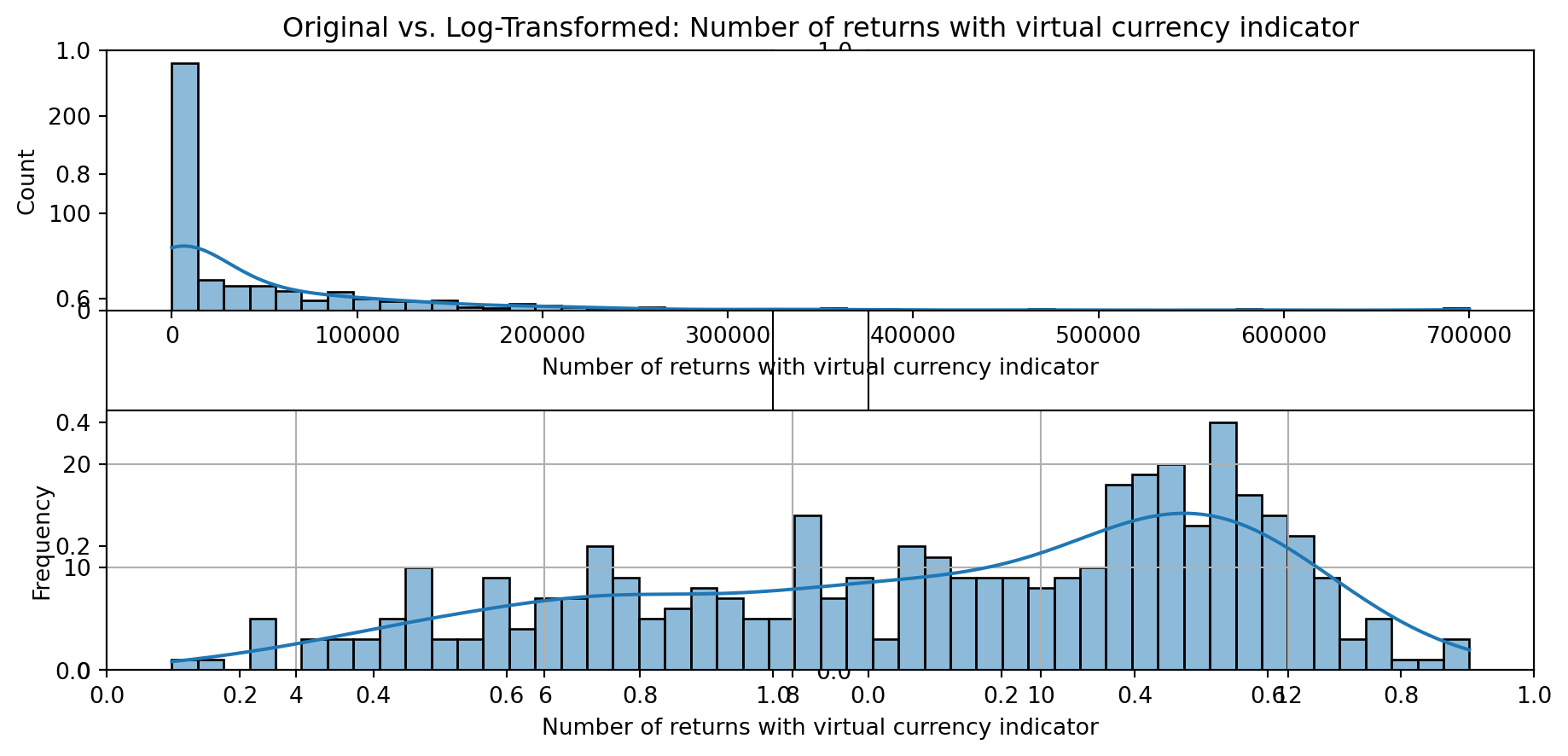
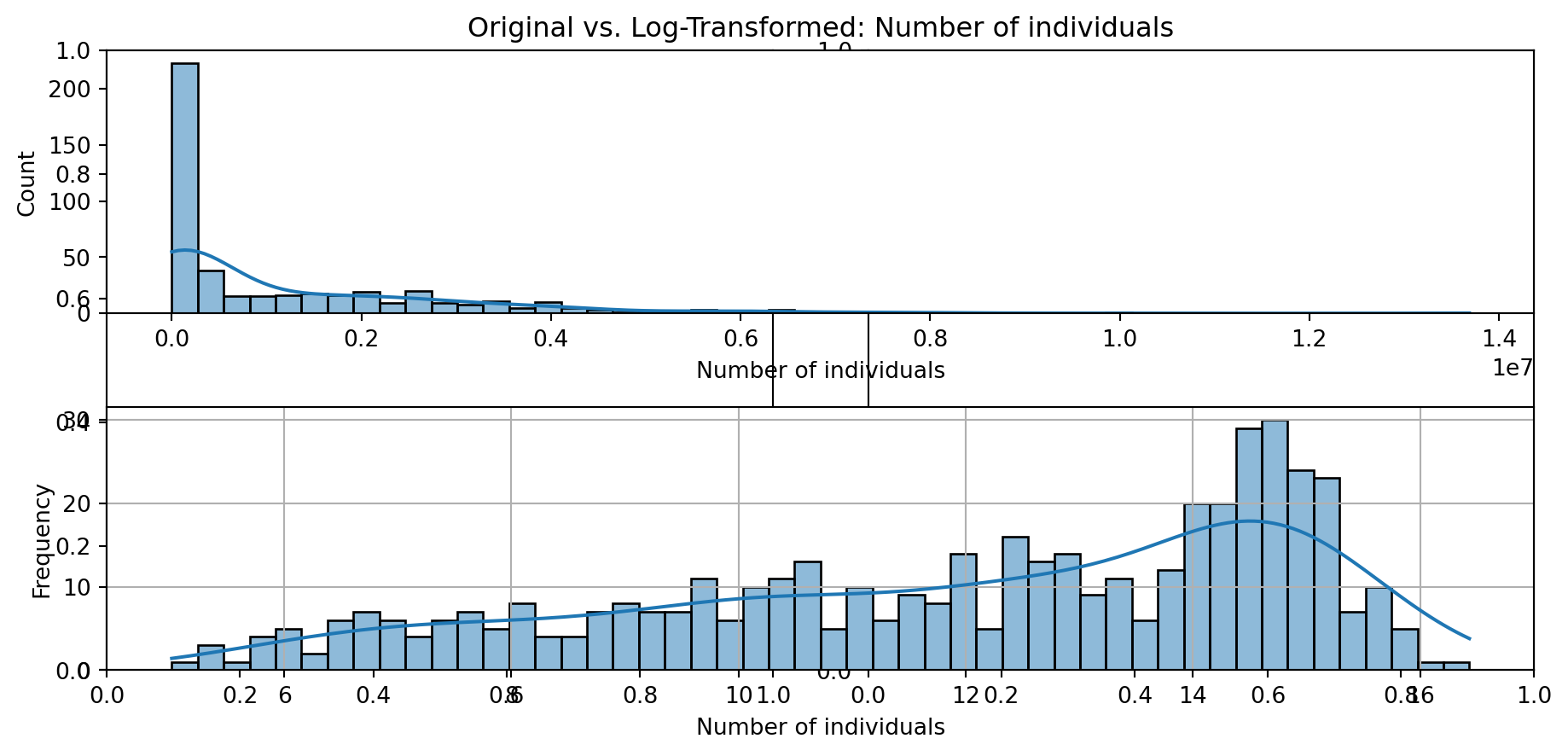
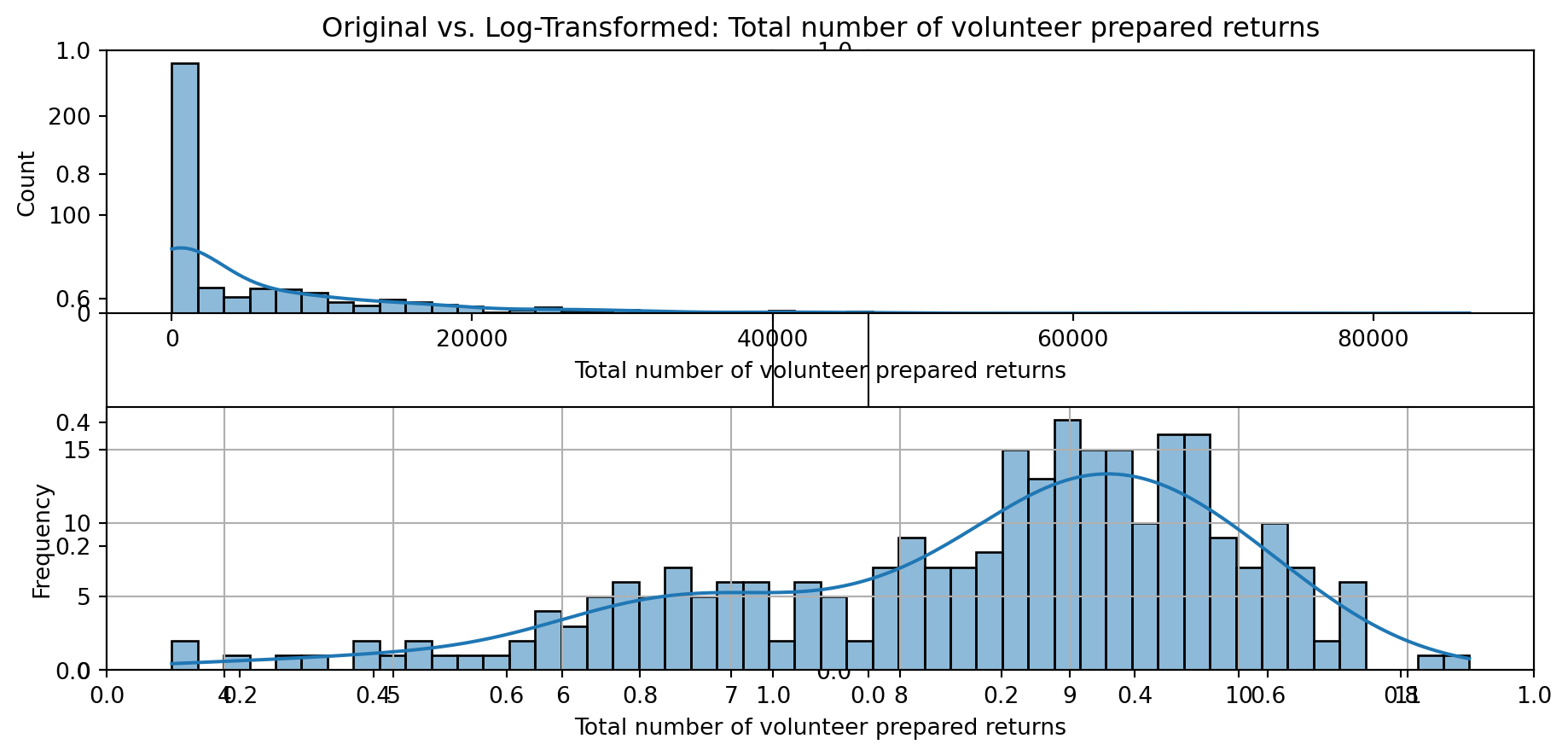
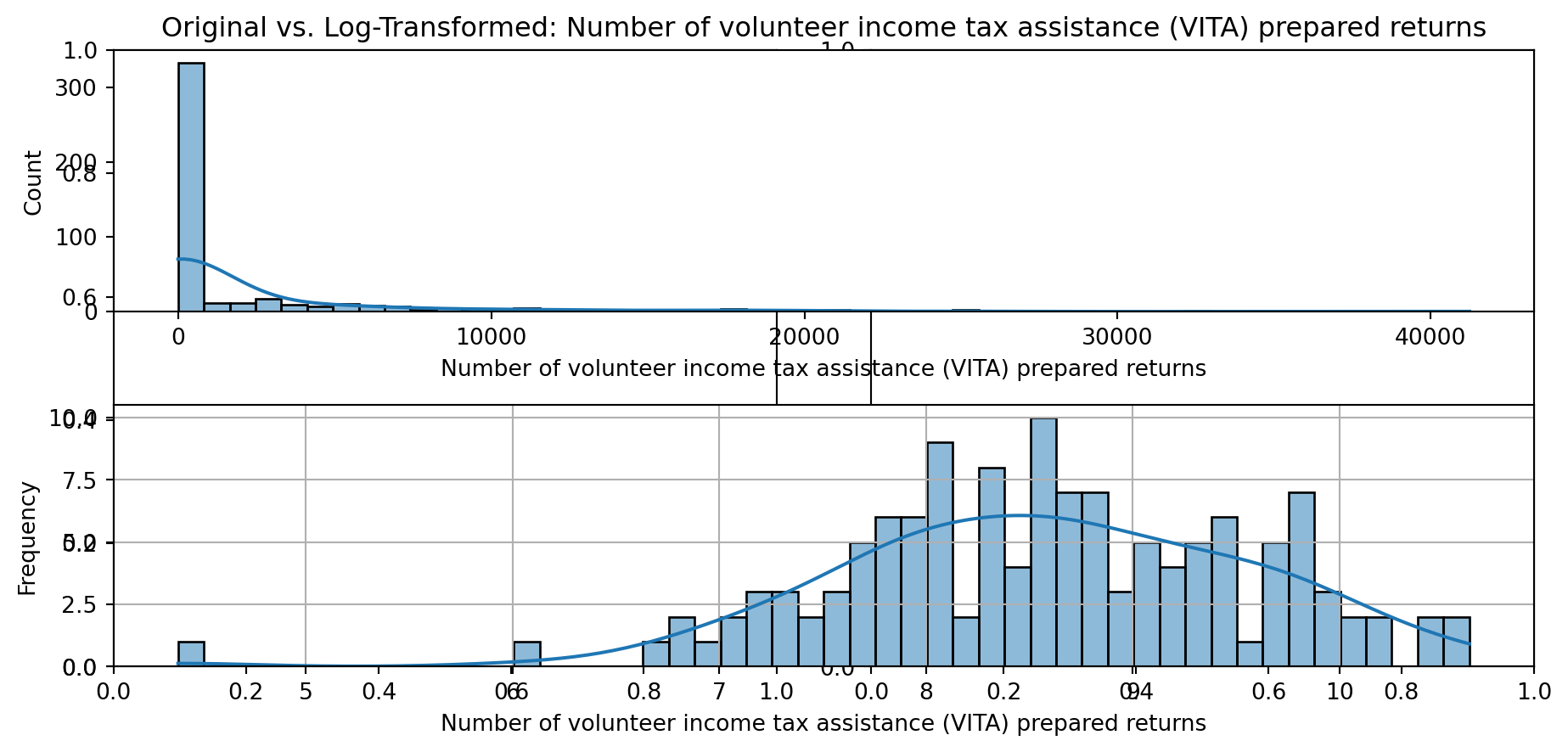
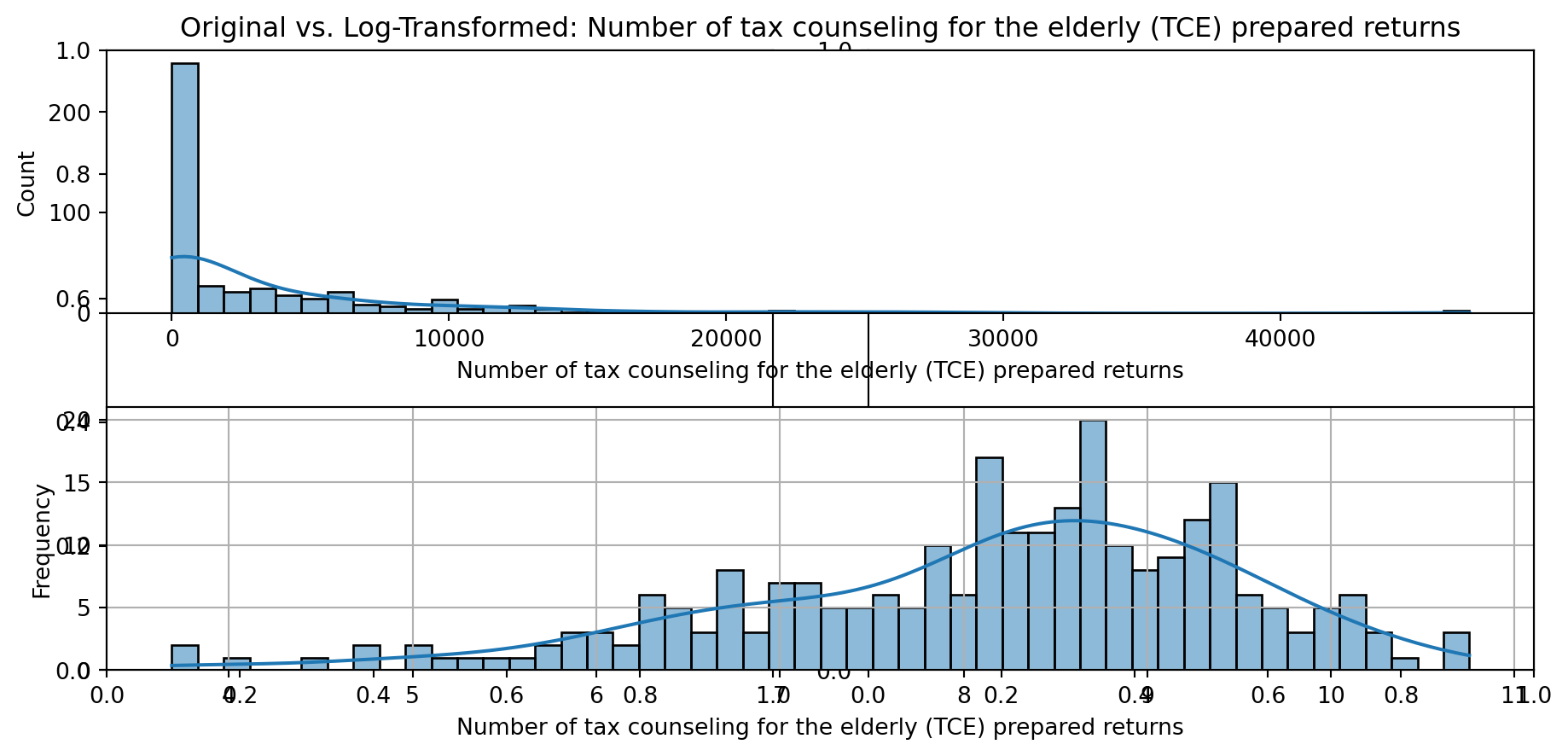
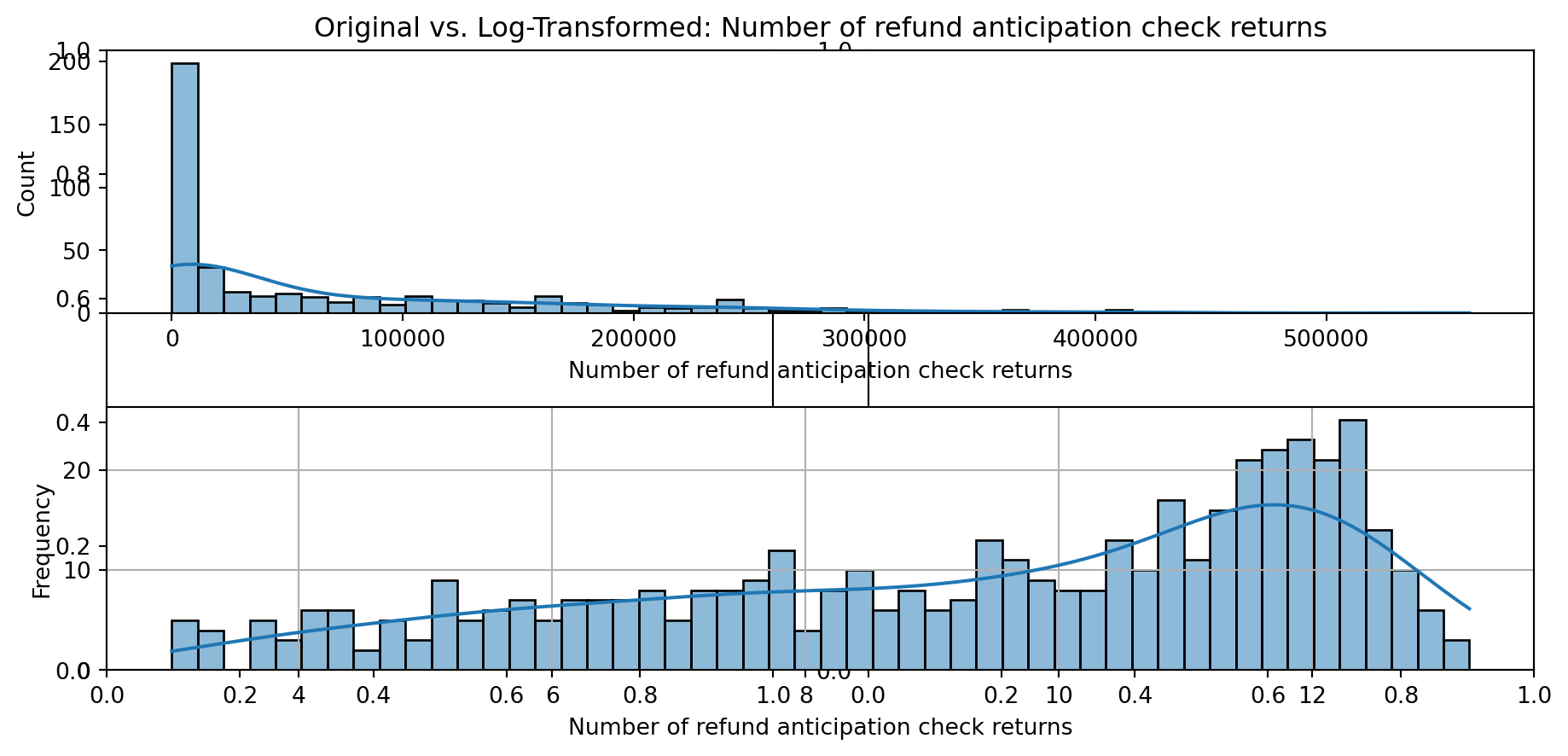
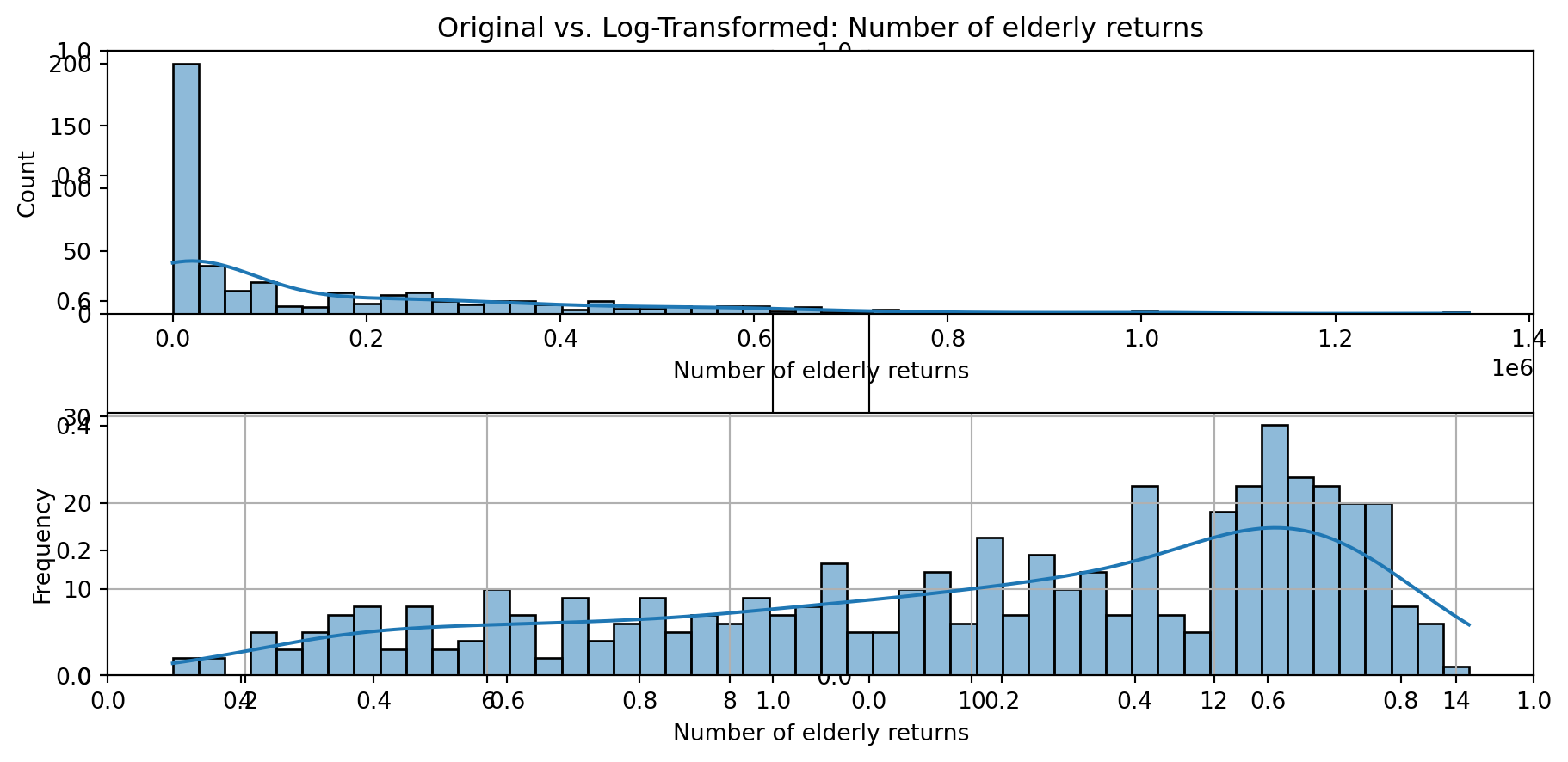
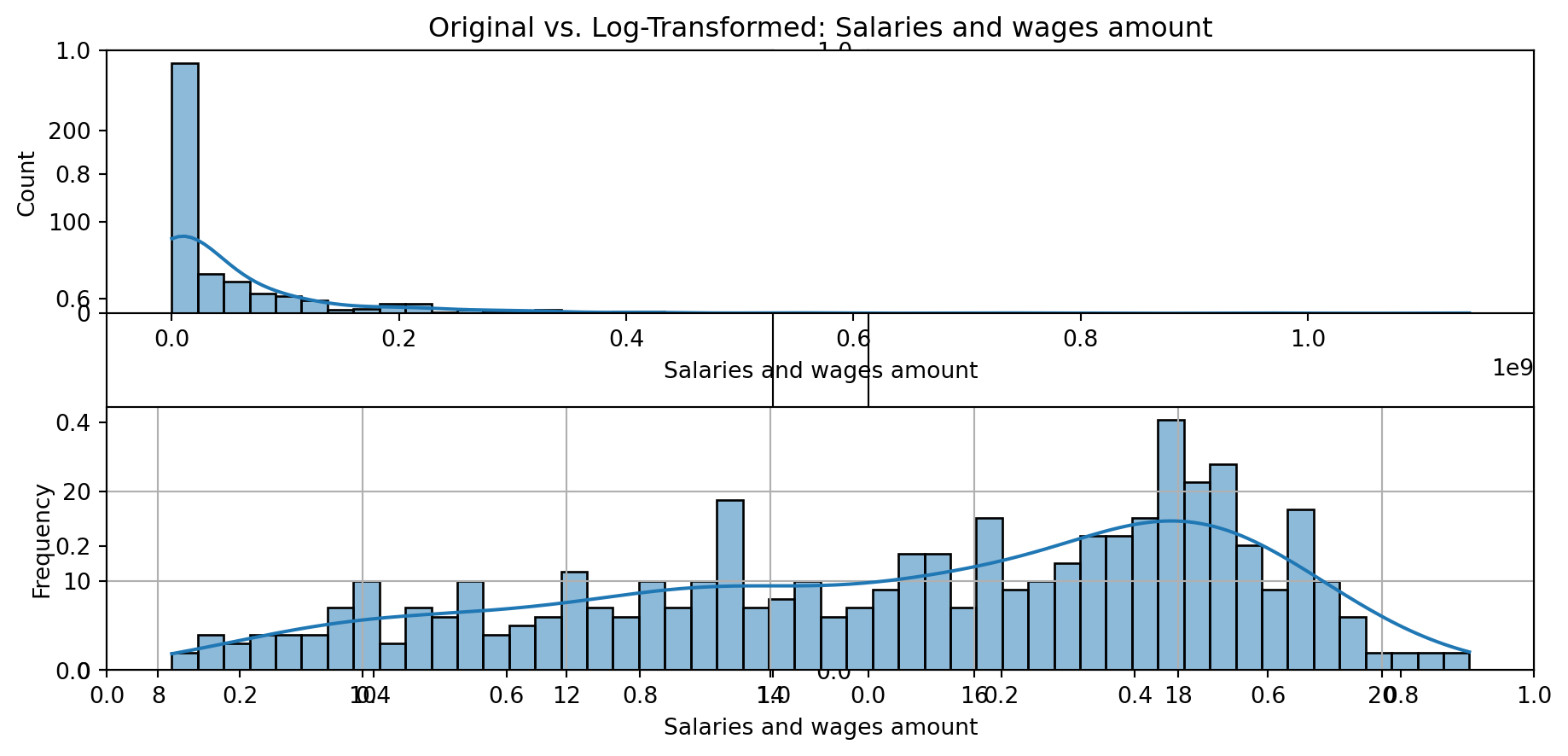


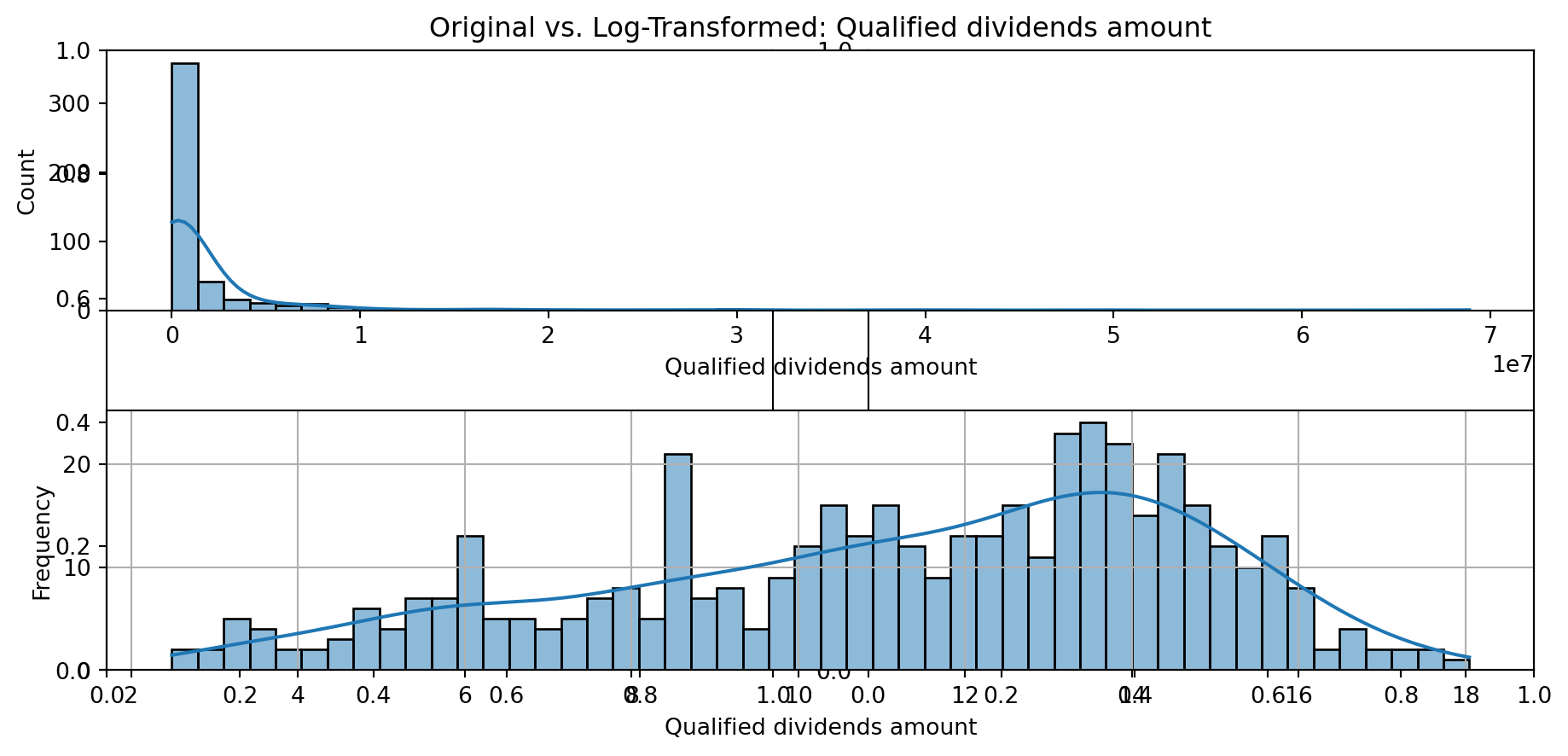


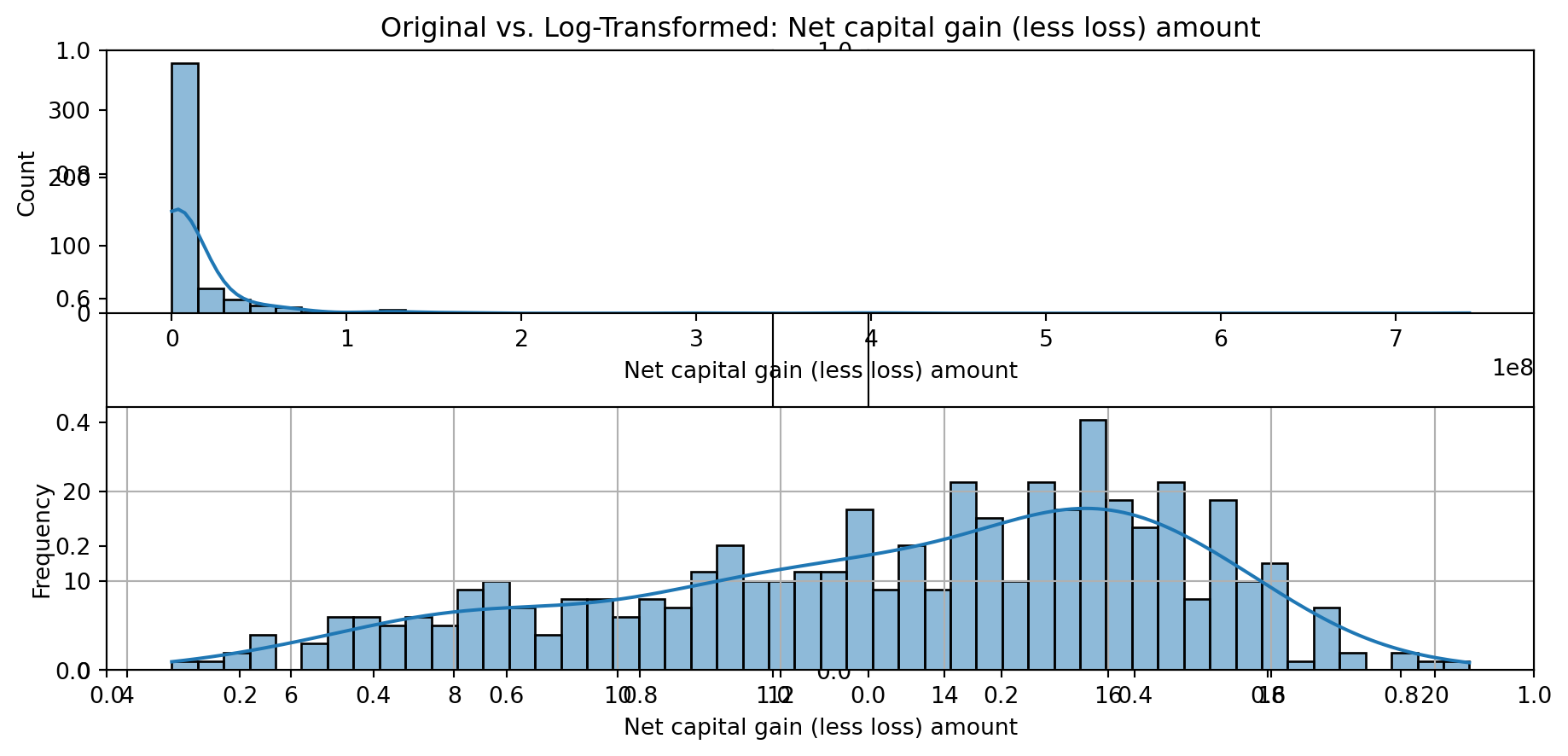
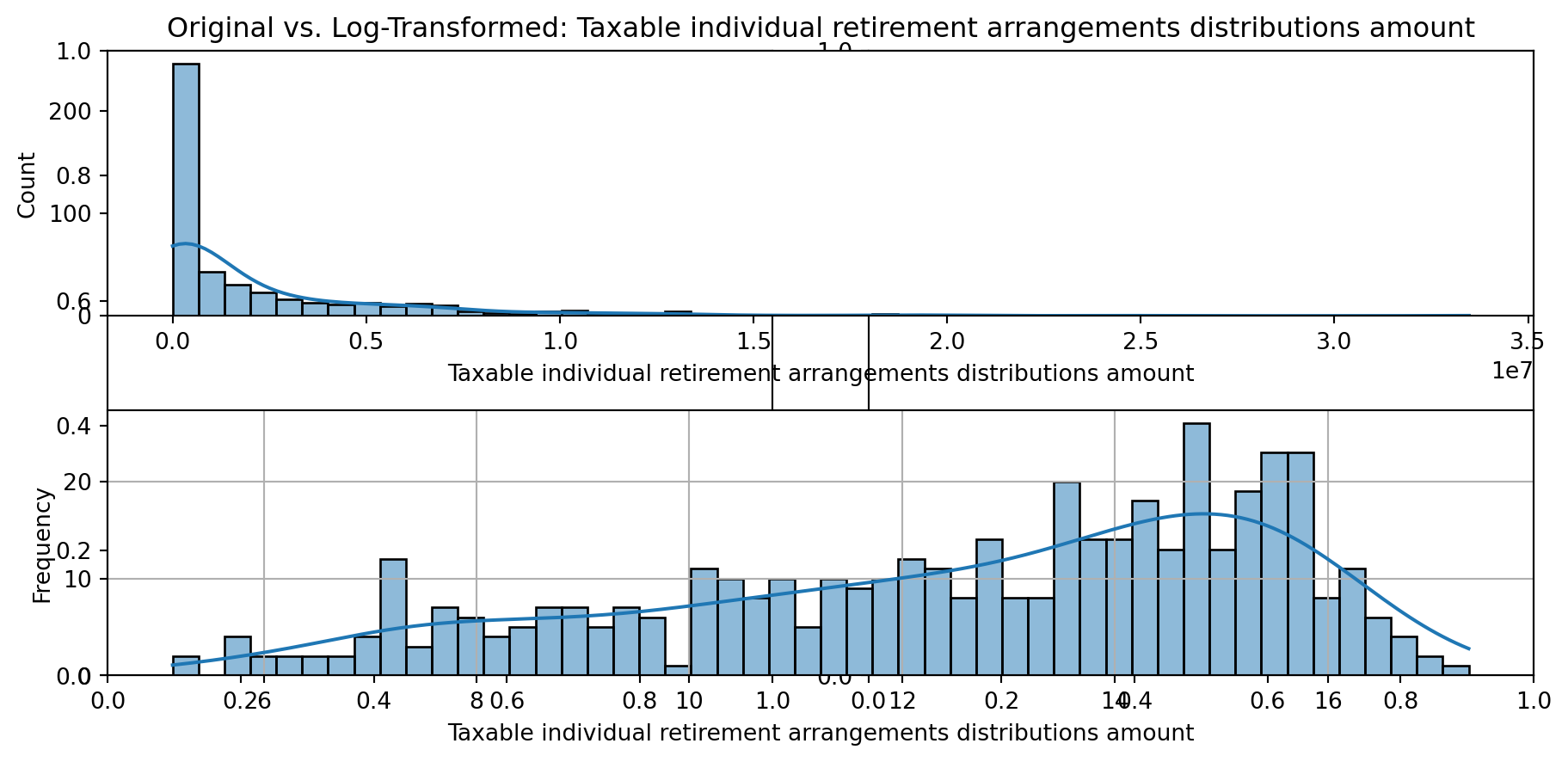

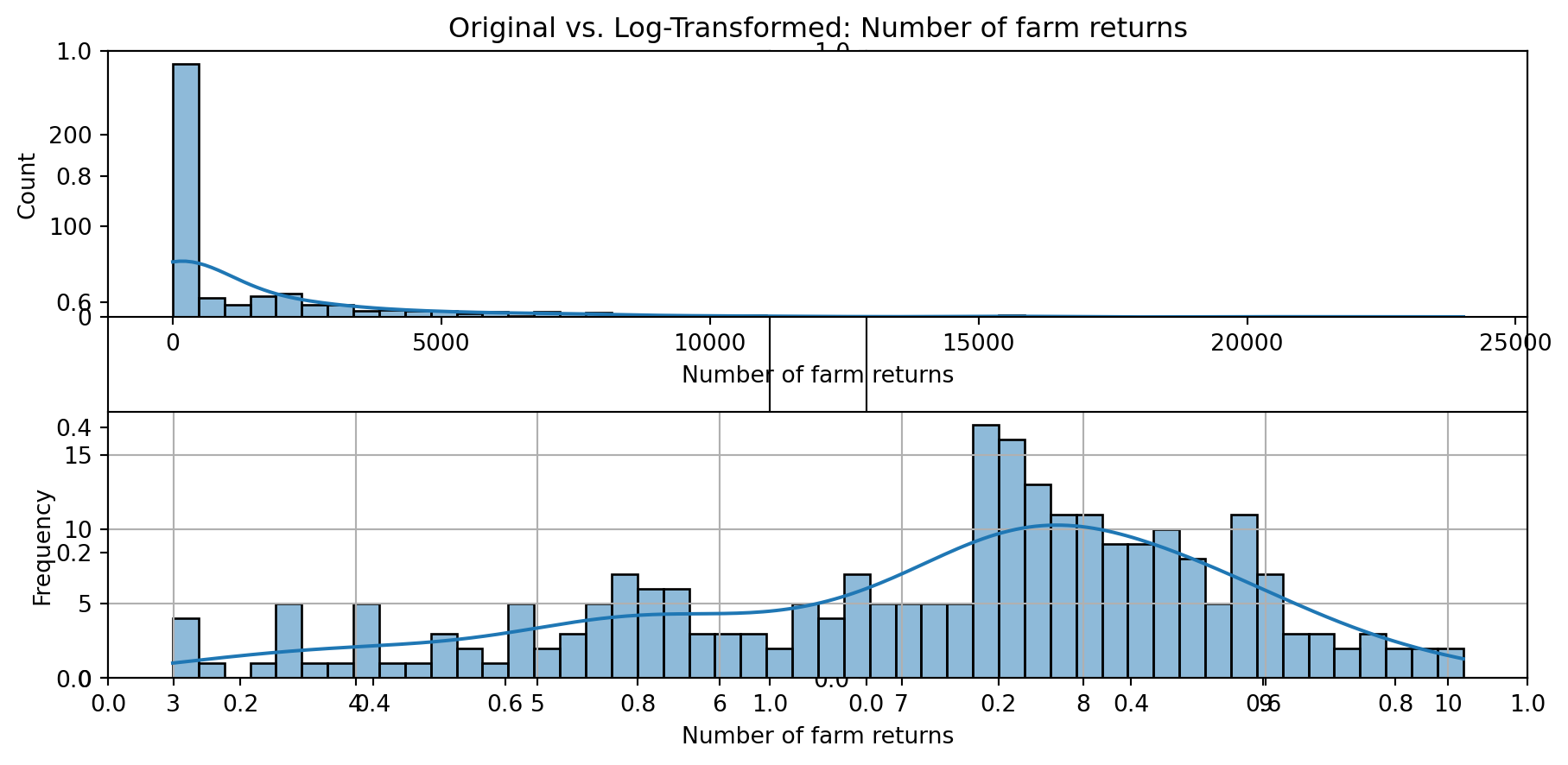
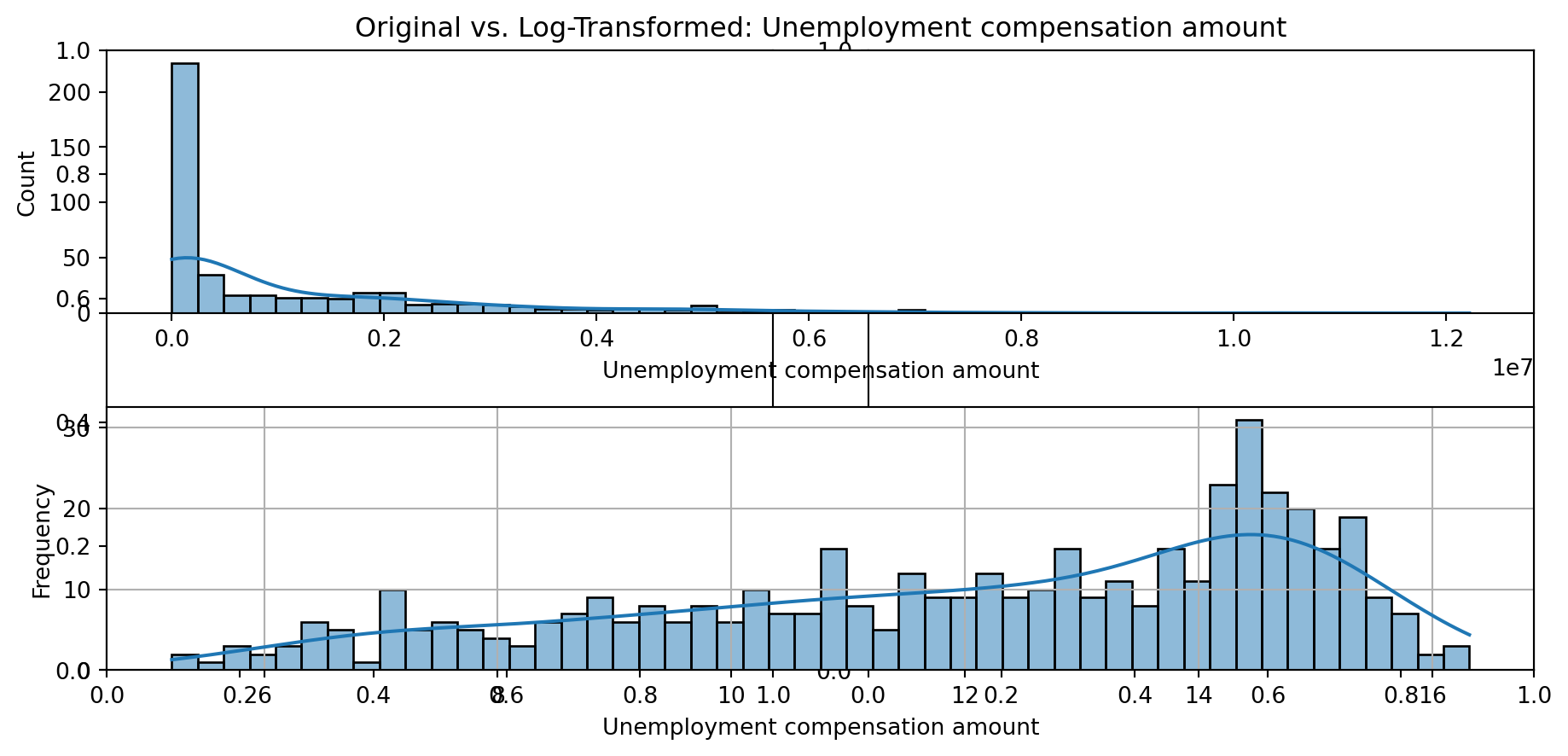
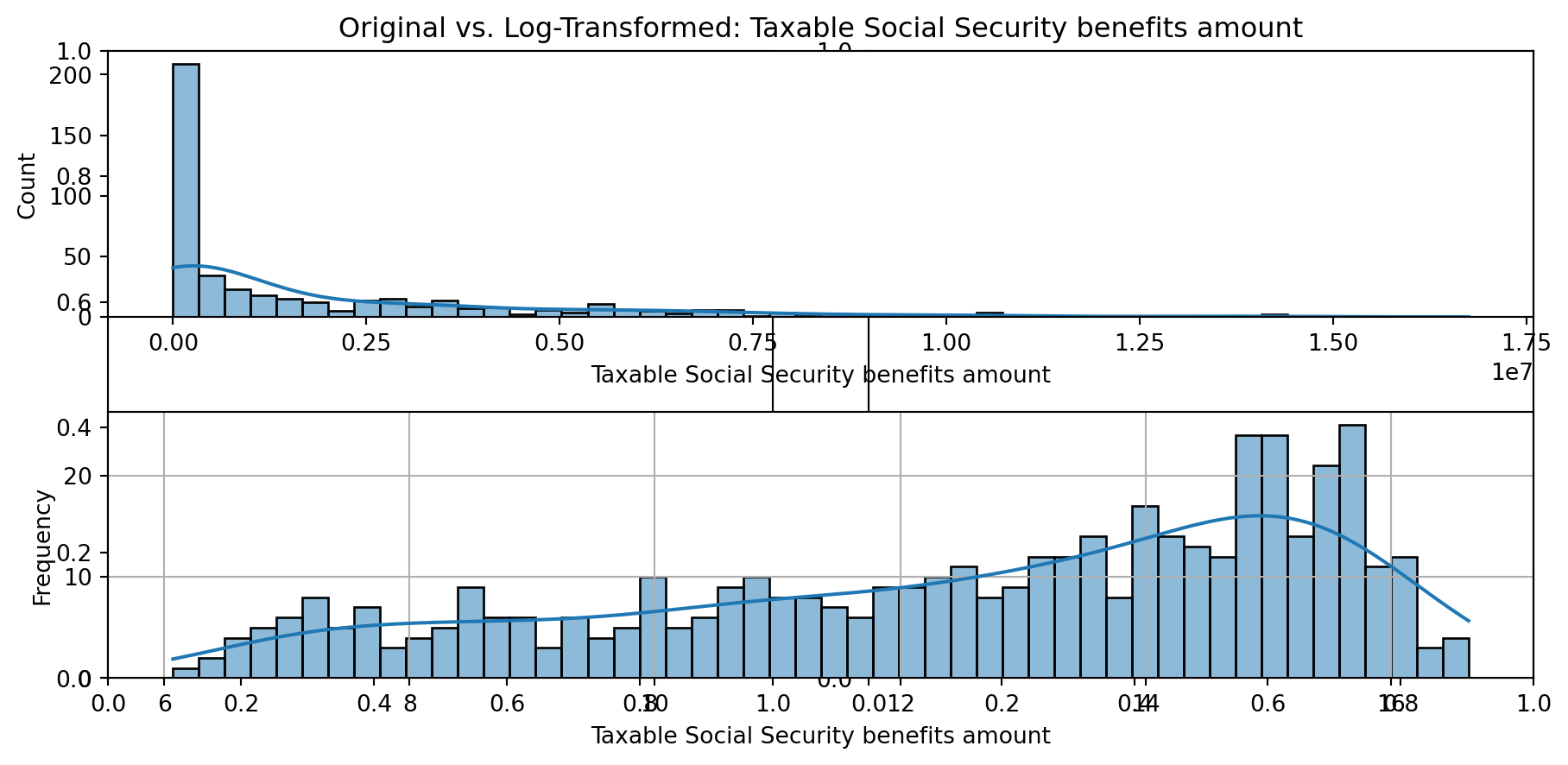

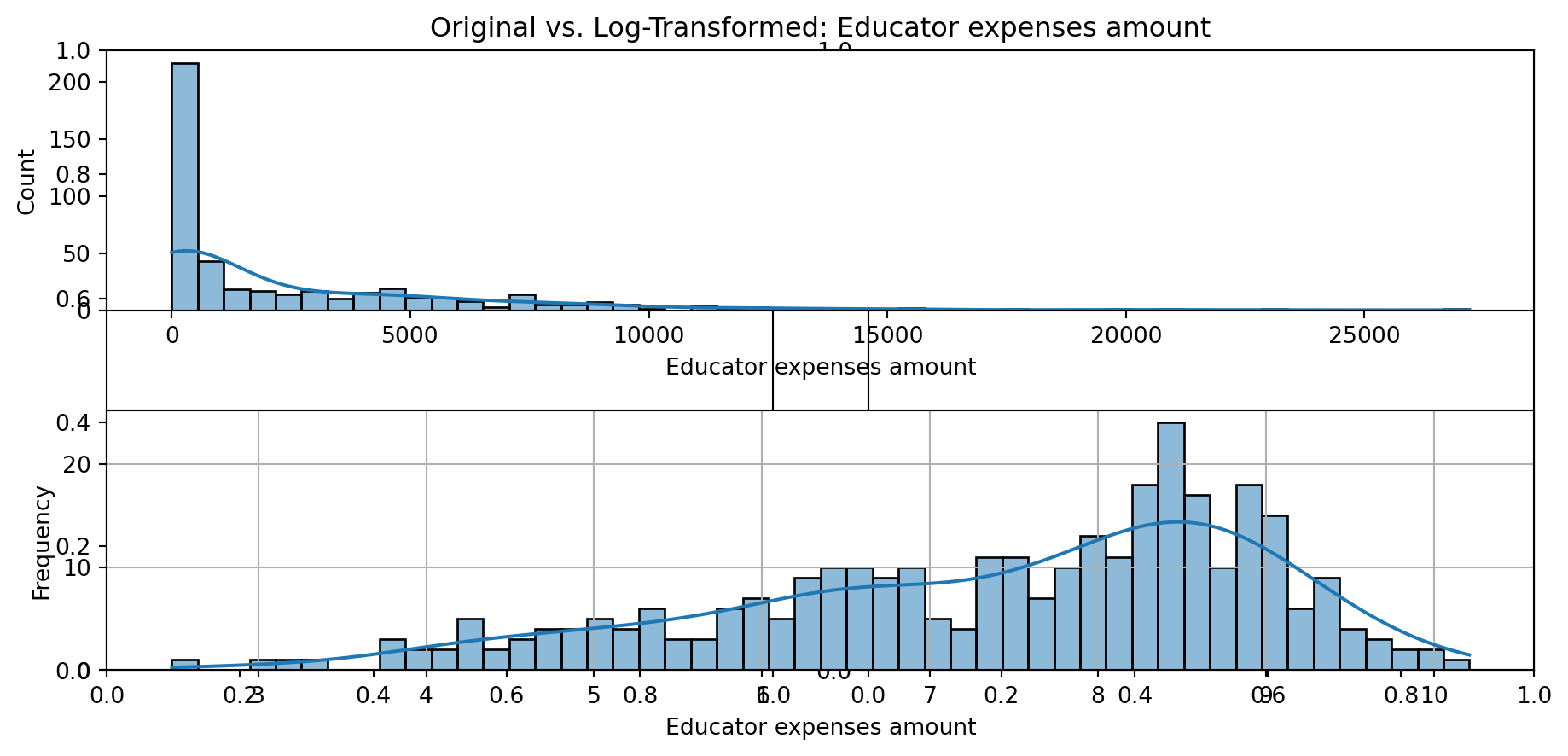
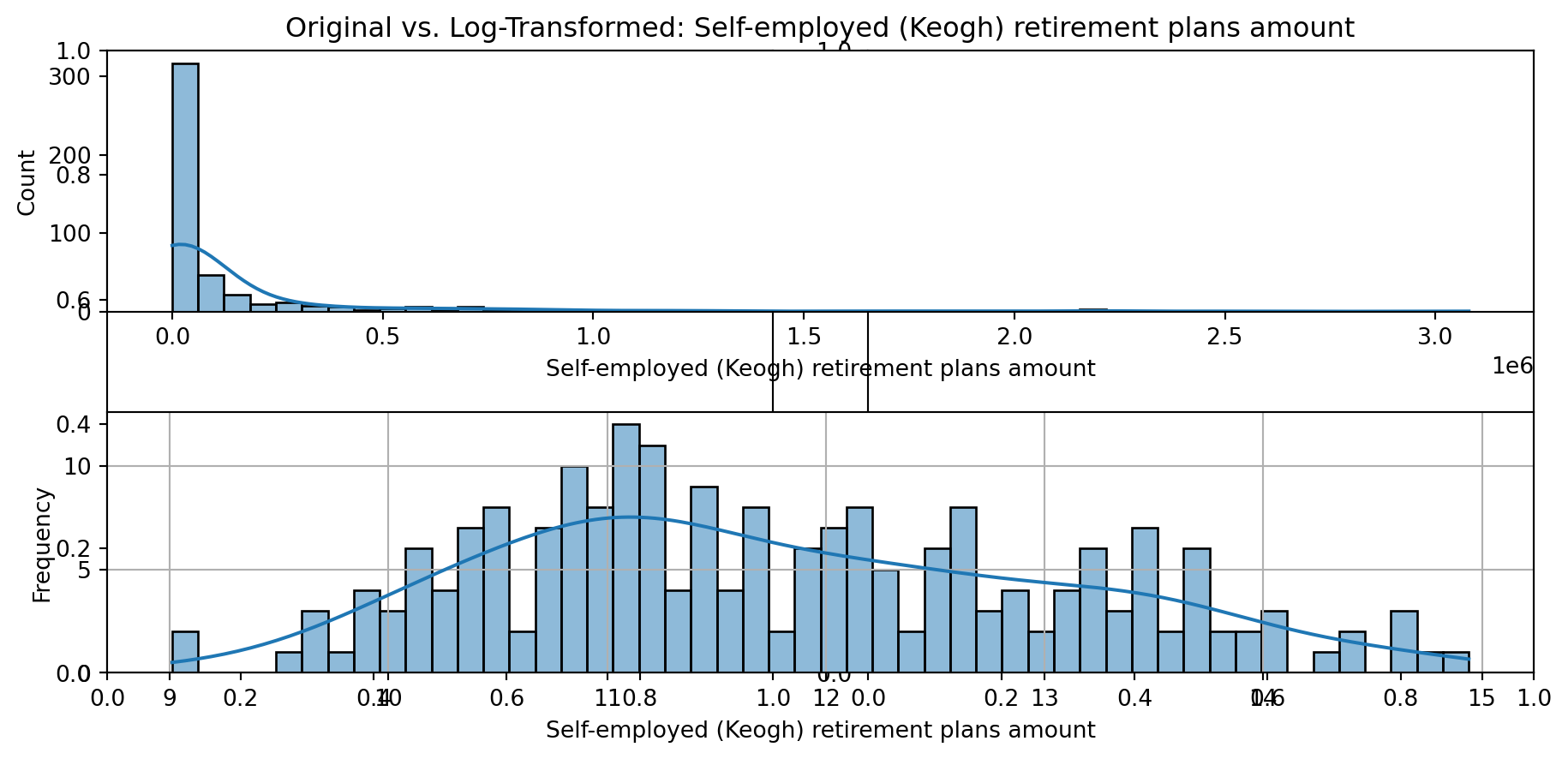



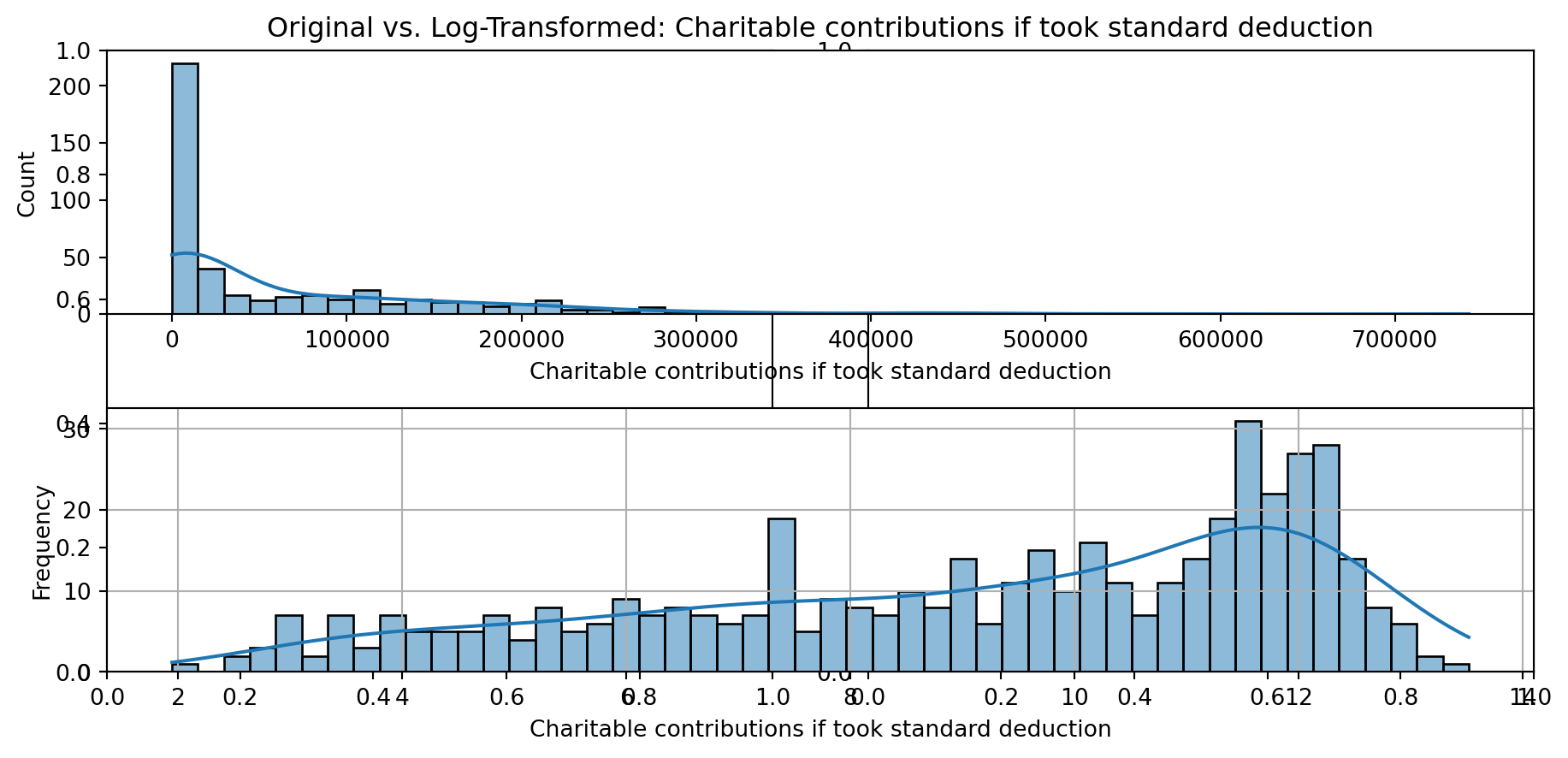





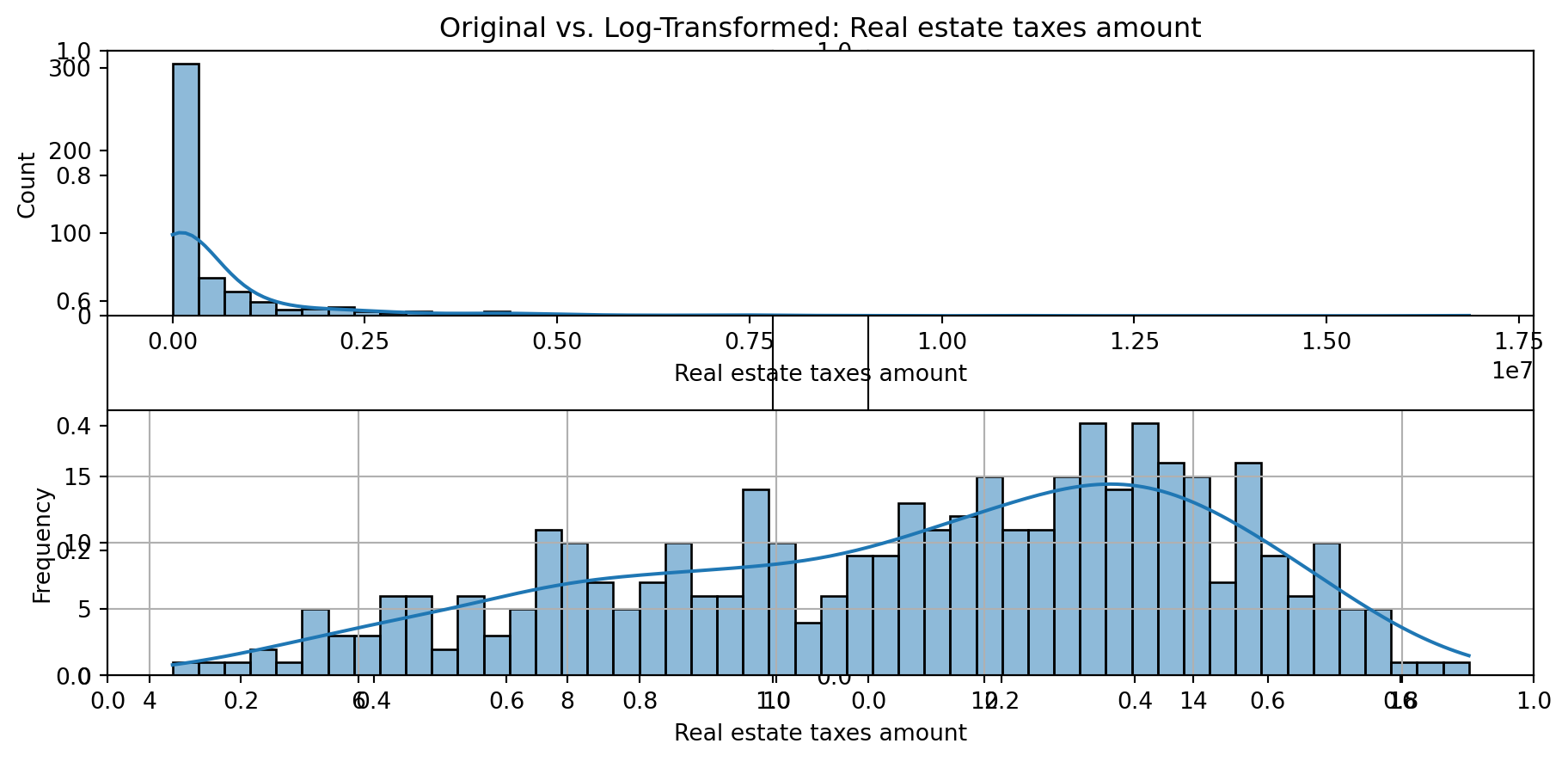
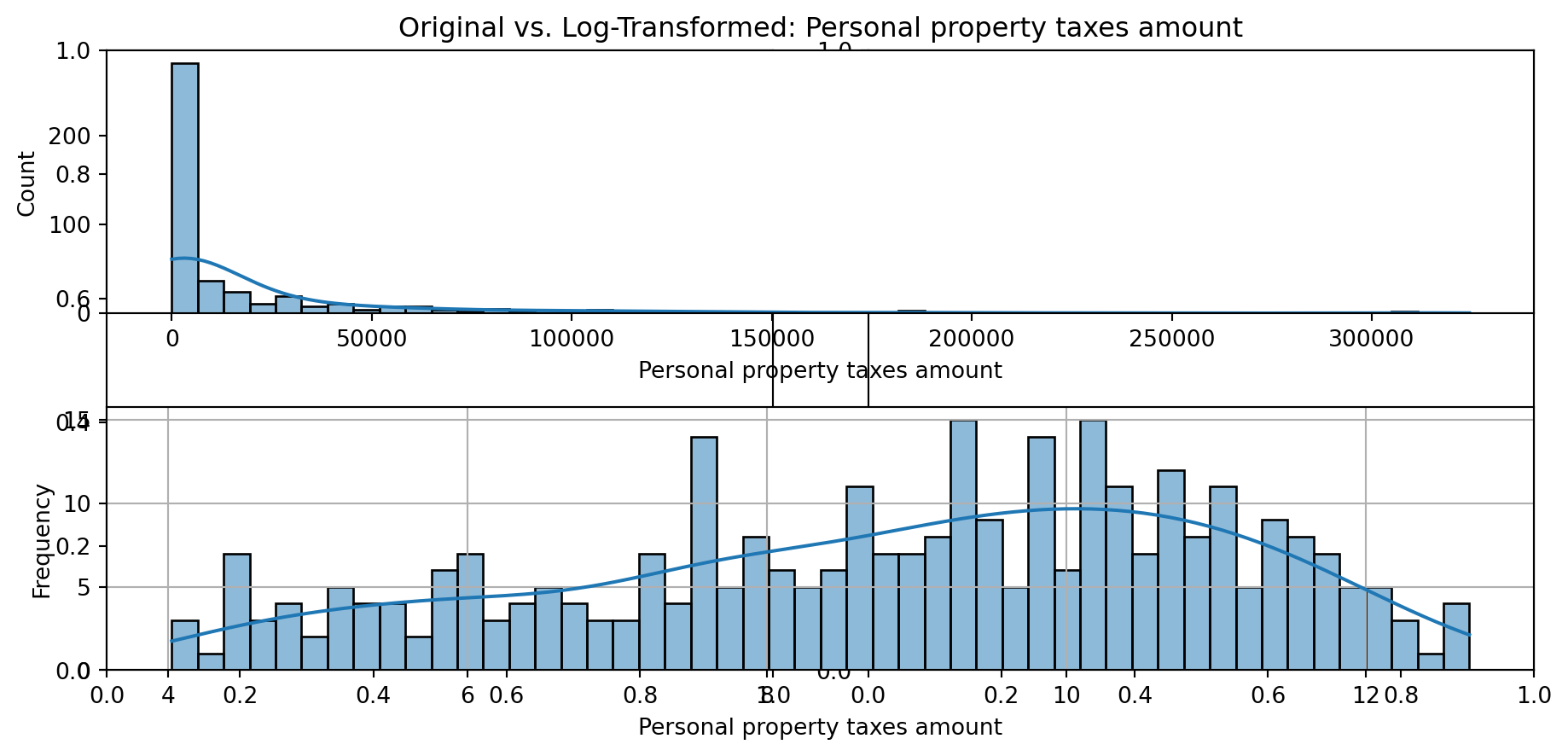
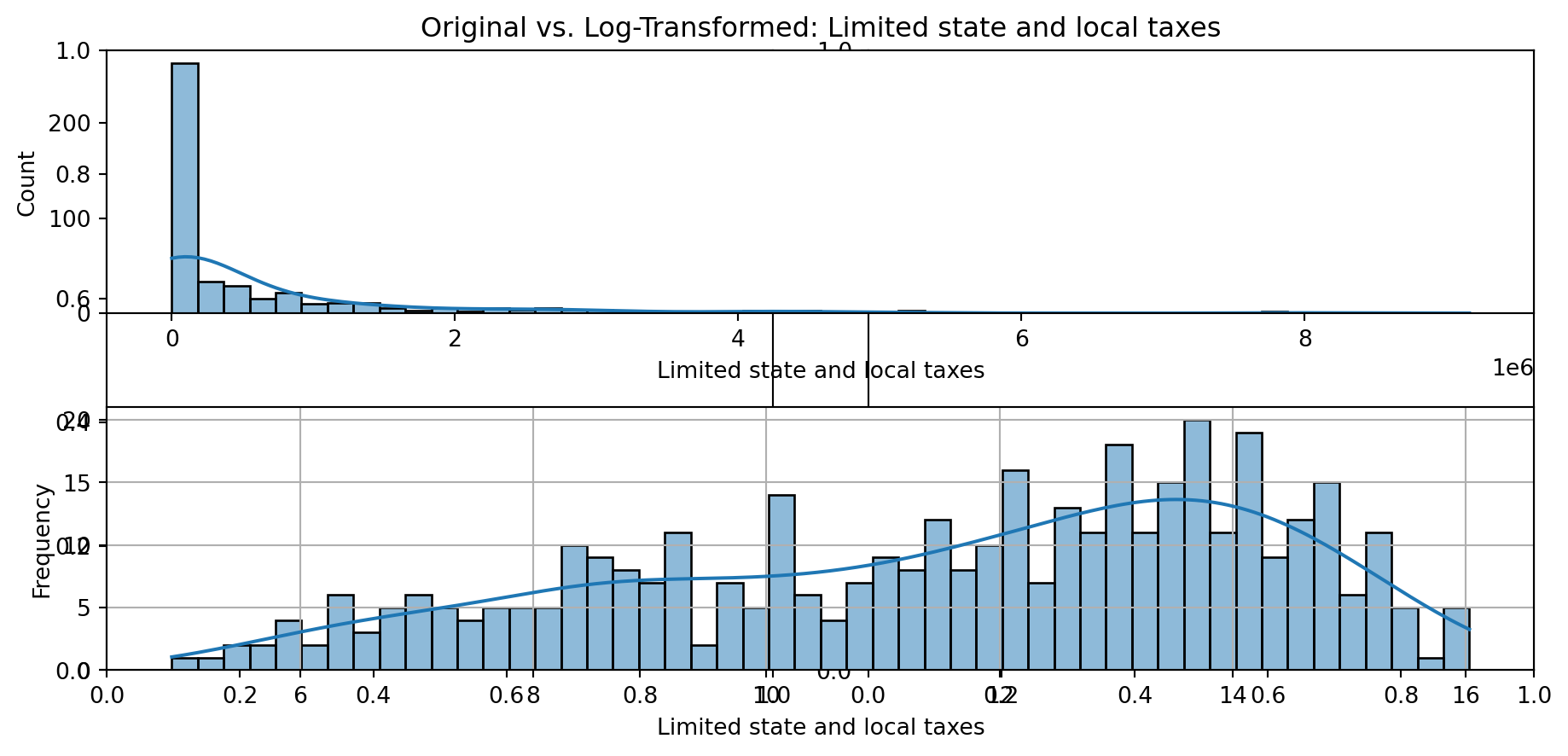
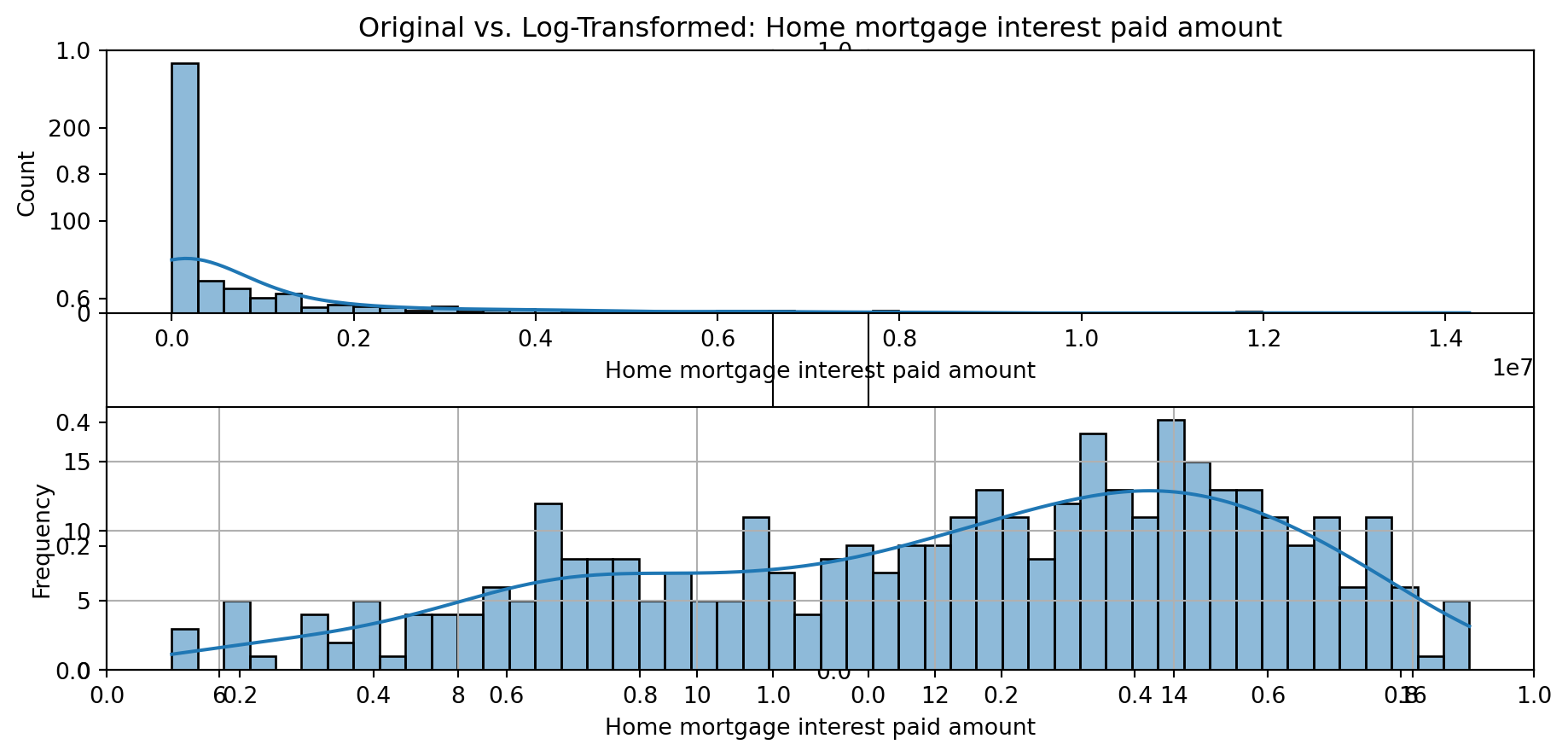
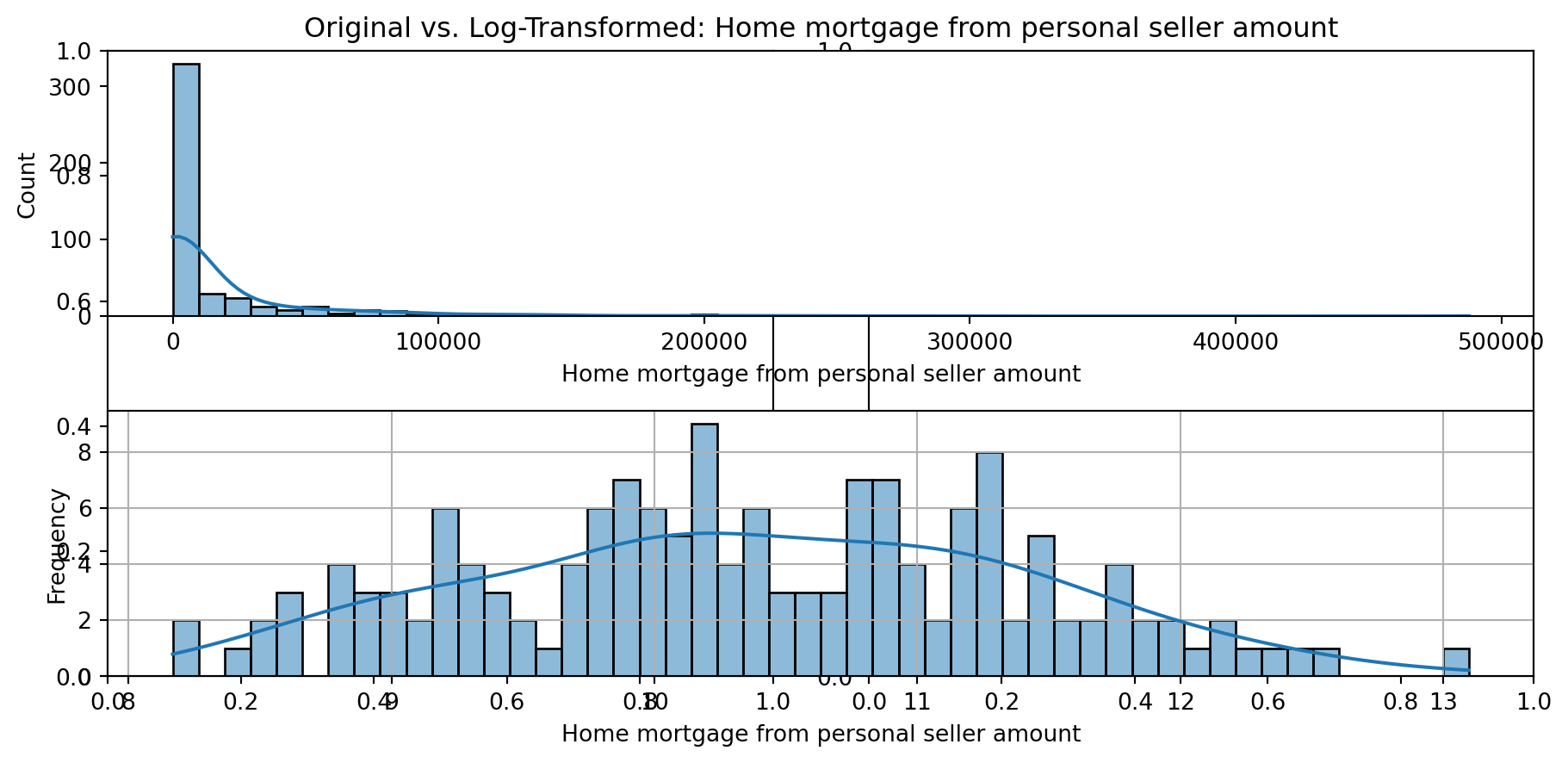


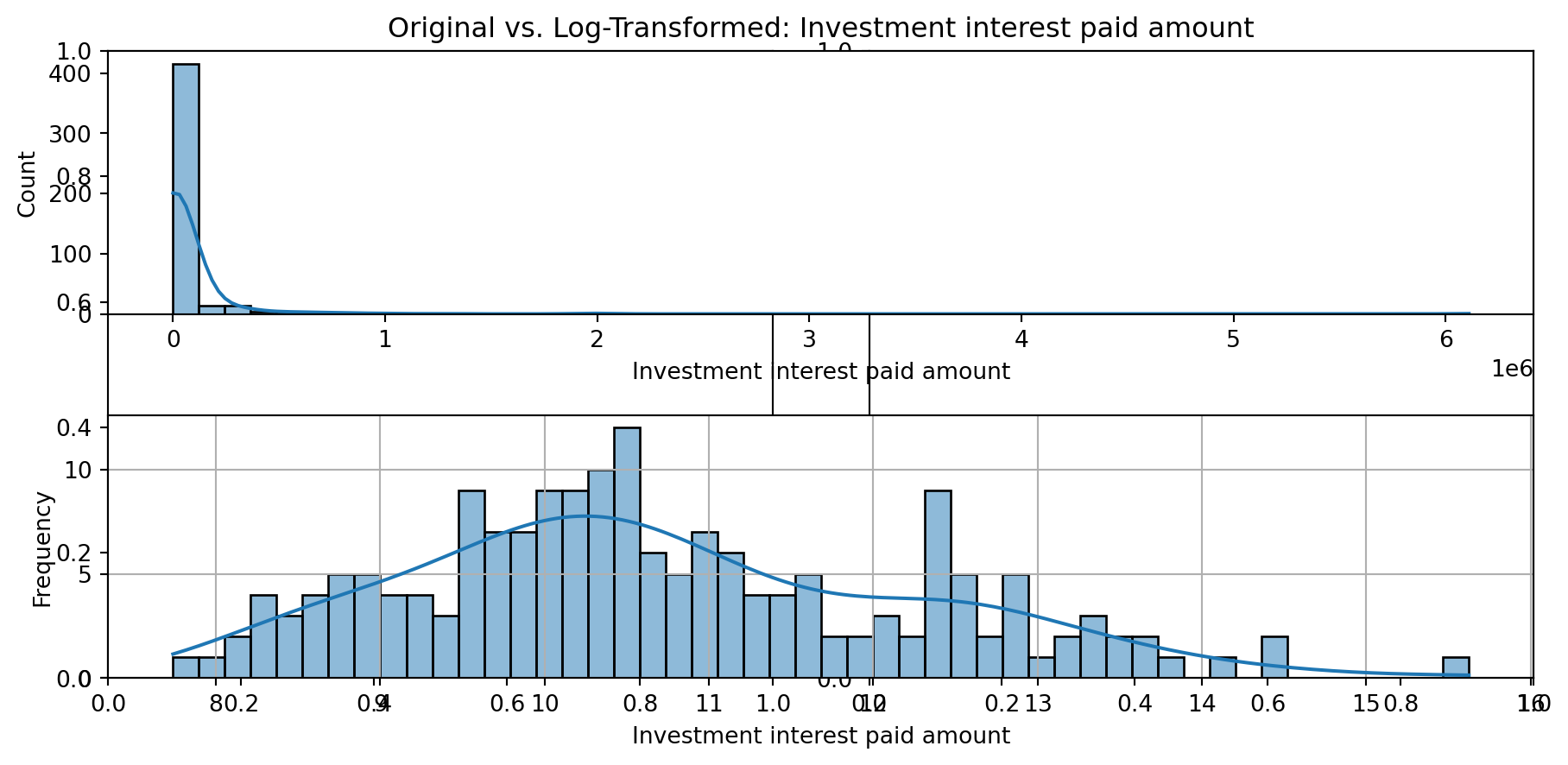
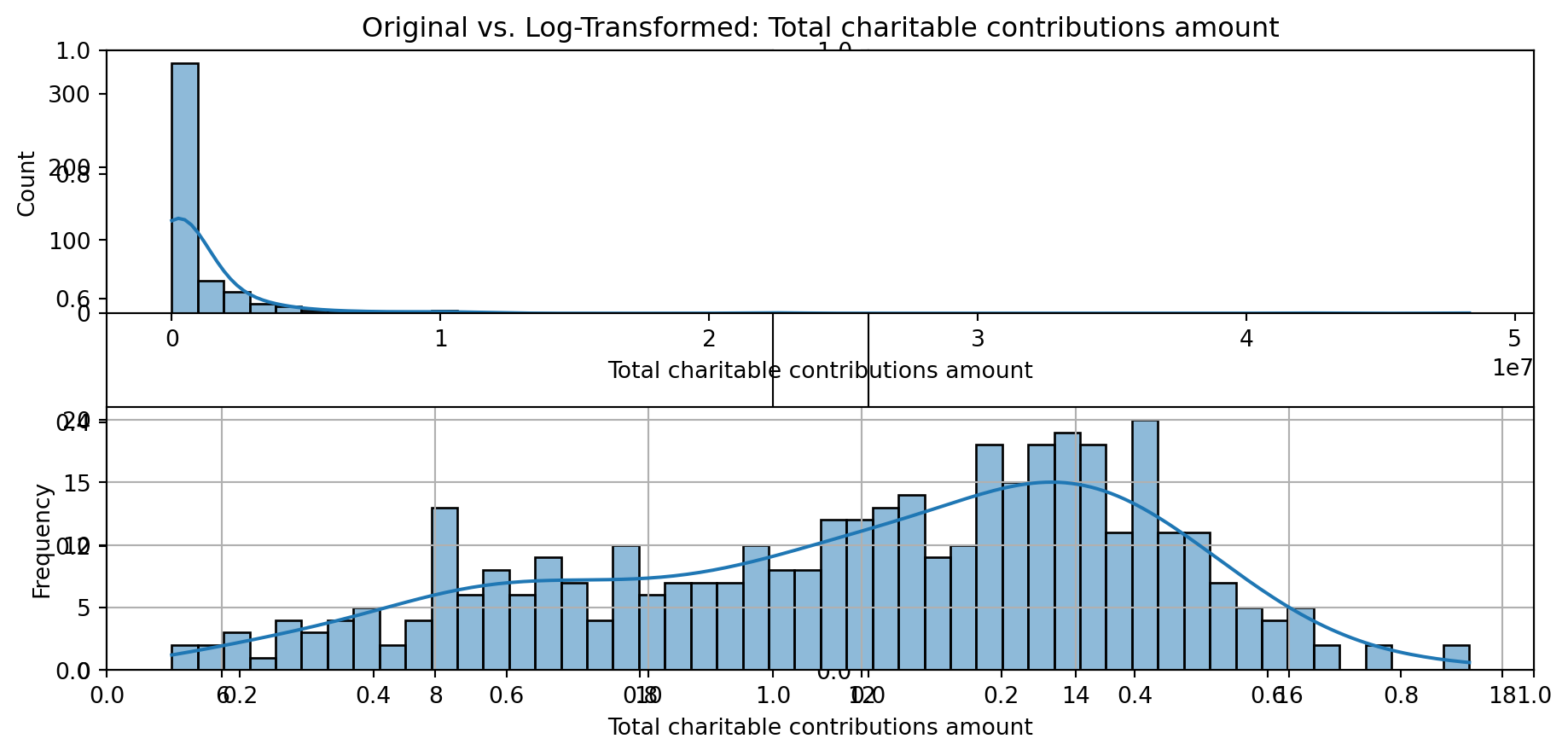


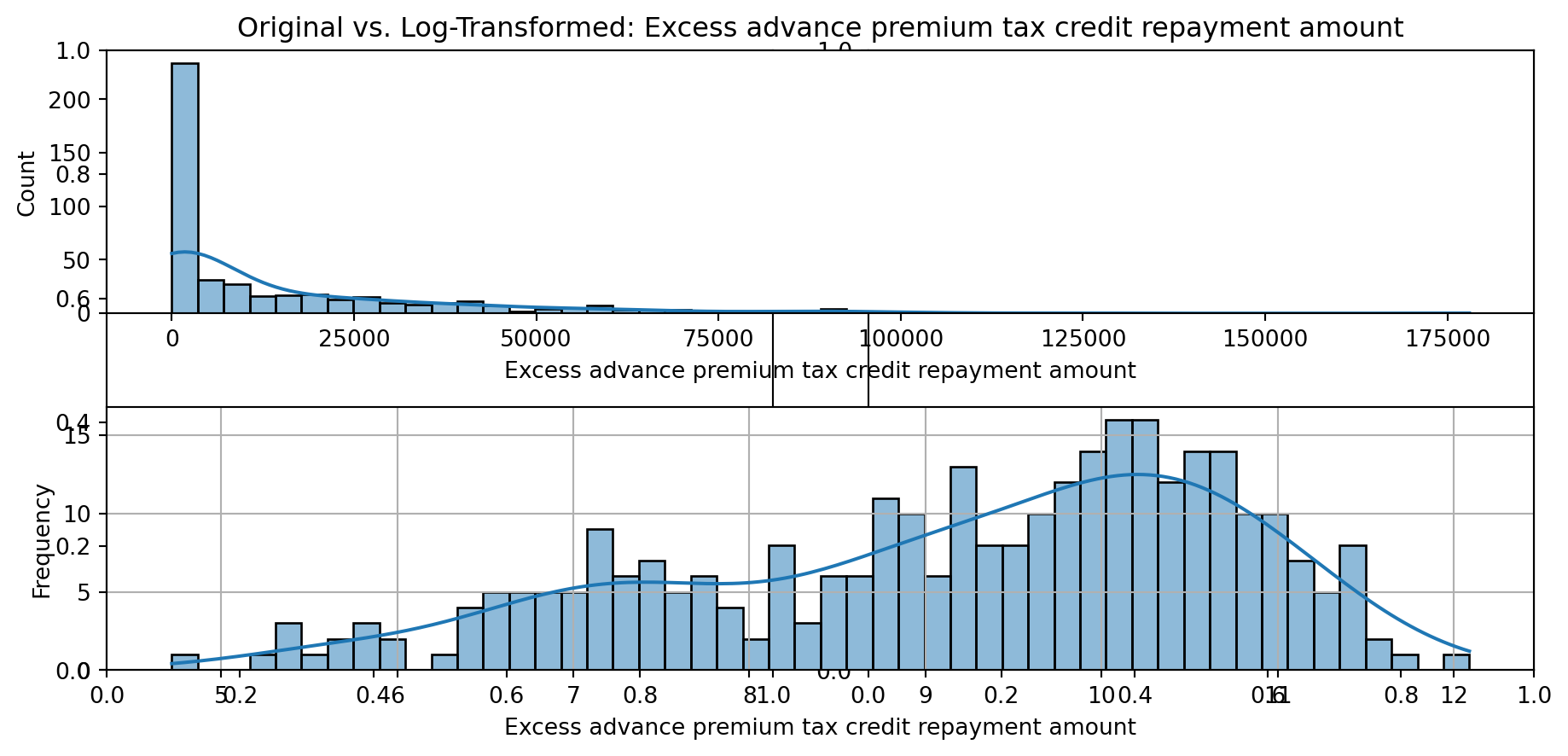

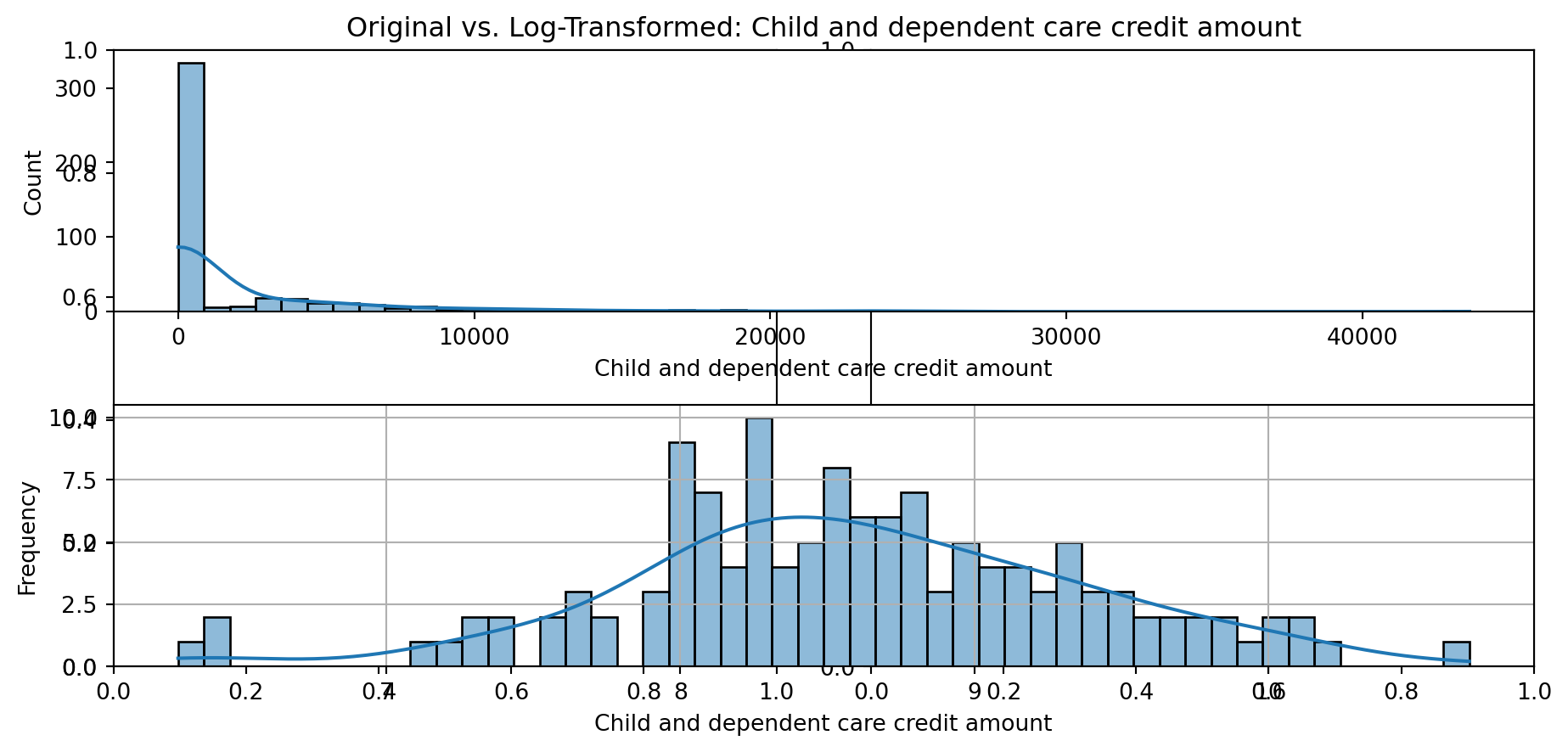



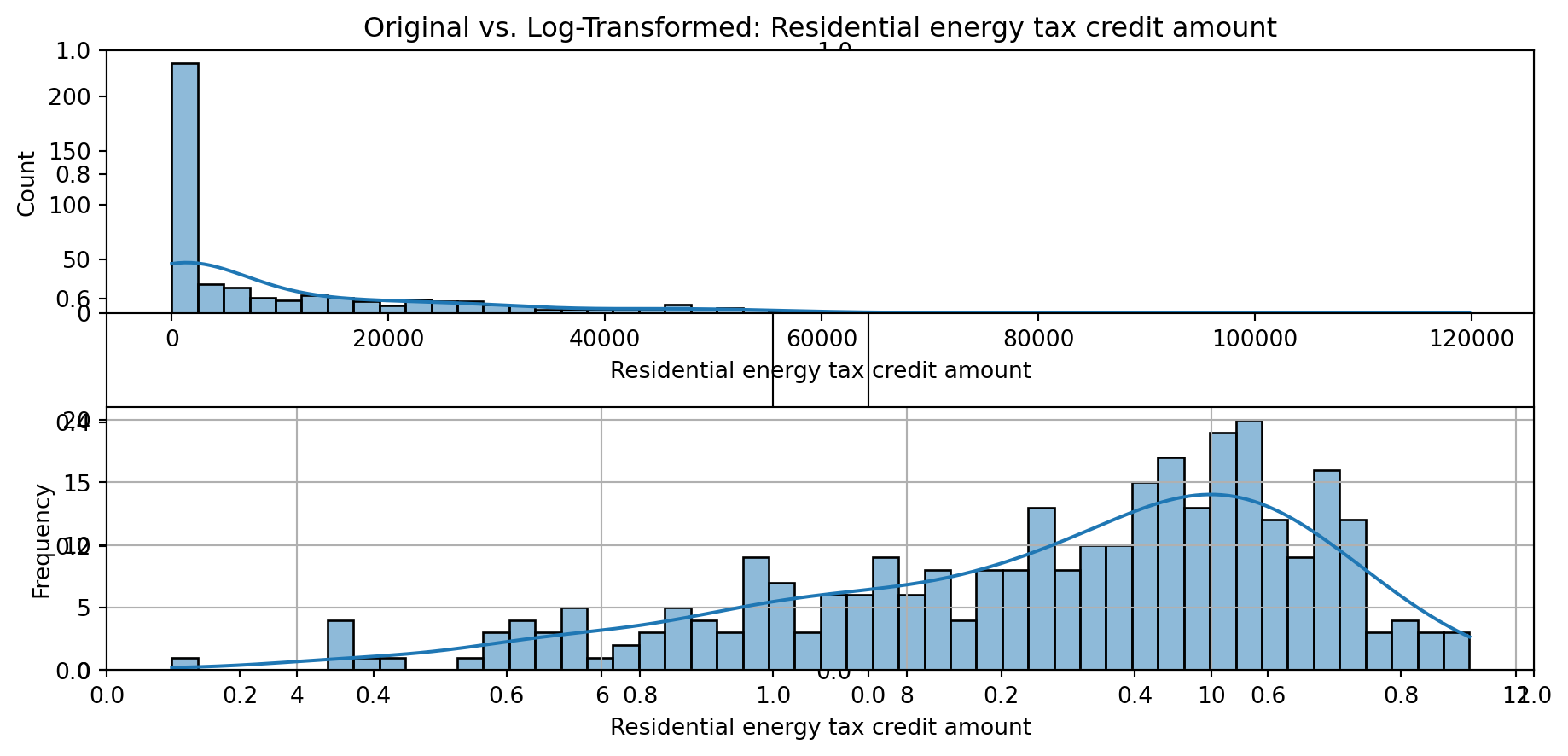













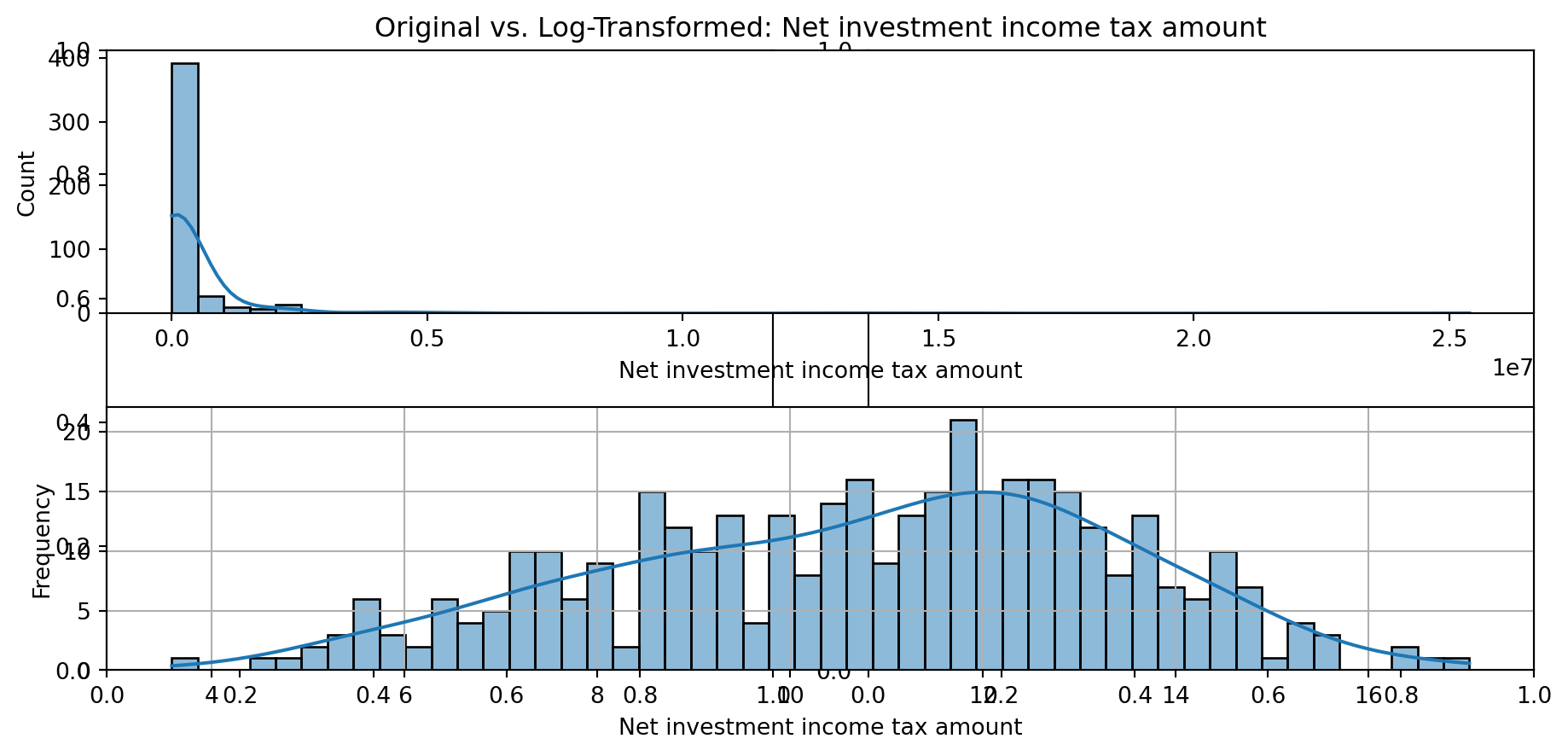

Boxplot Distributions
# Plot boxplot for each feature in the transformed dataset
def plot_transformed_feature_boxplots(data, data1):
for feature in data.columns:
fig, ax = plt.subplots(1, 2, figsize=(10,5))
ax1 = plt.subplot(2,1,1)
ax1 = sns.boxplot(data[feature])
ax2 = plt.subplot(2,1,2)
ax2 = sns.boxplot(data1[feature])
ax1.title.set_text(f'Original vs. Log-Transformed Boxplot of {feature}')
plt.xlabel(feature)
plt.ylabel('Frequency')
plt.grid(True)
plt.tight_layout()
plt.savefig(f'../../results/figures/boxplots/{feature}_boxplot.png')
plt.show()
# Plot the boxplots for the log-transformed features
plot_transformed_feature_boxplots(X_grouped, X_transformed)